Entries tagged 'mysql'
Maintenance engineer, slightly used
A popular response to the attempted backdooring of the XZ Utils has been people like Tim Bray talking about the maintenance of open source projects and how to pay for them.
When I transitioned from leading the web development team at MySQL to an engineering position in the server team, I spent the first year as a maintenance engineer. I blogged a little about the results of that one year and calculated that I had fixed approximately one reported bug per working day.
But you’ll also notice that I had to heap some praise on Sergei Golubchik who reviewed fixes for even more bugs than I had fixed. (He also was responsible for working on new features. He is extremely talented, and I’m not surprised to see he’s the chief architect at MariaDB.)
That sort of reviewing and pulling in patches is a critical component of maintaining an open source project, and a big problem is that is not all that fun. Writing code? Fun. Fixing bugs? Often fun. Reviewing changes, merging them in, and making releases? A lot less fun. (Building tools to do that? More fun, and can sidetrack people from doing the less-fun part.)
It is also a lot different for projects with a lot of developers, a small crowd of developers, and just a few developers. The process that a patch goes through to make it into the Linux kernel doesn’t necessarily scale down to a project with just a few part-time developers, and vice versa. A long time ago, I made some noise about how MySQL might want to adopt something that looked more like the Linux kernel system of pulling up changes rather than what was the existing system of many developers pushing into the main tree, and nobody seemed very interested.
Anyway, as people think about creating ways of paying people to maintain open source software, I think it is very important to make sure they don’t inadvertently create a system that bullies existing open source project maintainers to make them focus on the less-fun aspects to developing software, because that’s kind of how we got into this latest mess.
You already see that happening with supposed-to-be-helpful supply chain tools demanding that projects jump through hoops to be certified, or packaging tools trying to push their build configuration into projects (with an extra layer of crypto nonsense), or a $3 trillion dollar company demanding a “high priority” bug fix from volunteers.
I am curious to see where these discussions lead, because there is certainly not one easy solution that is going to work everywhere. It will also be interesting to see how quickly they lose steam as we get some distance from the XZ Utils backdoor experience.
(Also, I’m still looking for work, and I’m willing to do the less-fun stuff if the pay is right.)
Thoughts from SCALE 21x, day 1

Today was the first day of the 21st Southern California Linux Expo, also known as SCALE 21x. I gave a talk at way back at SCALE 4x and hadn’t made it back since then.
I attended a couple of talks on the UbuCon track at the beginning of the day. They weren’t technical talks, but focused on how the Ubuntu community operates and how Canonical relates to that. It sounds like Canonical has opened itself up more to the community by adopting Matrix as both their internal communications tool as well as what the community uses, which I think is very important for encouraging the developers in a commercial open source environment to engage with the community. This was an issue for us back in the MySQL days, too.
(There was also a comment about “neck beards” being annoying about not adopting newer communication tools and wanting everyone to stick with IRC, I think coming from someone involved with openSUSE, which I thought was kind of funny.)
After that, I popped over to the beginning of the Kwaai Personal AI Summit because Doc Searls was giving a (brief) talk and I thought I would see if there was anything to this AI thing that I’ve been hearing about. The room had a lot of old dude energy that just wasn’t sitting right with me, so I ended up bailing after Doc’s talk.
Since I left that earlier than I had planned, I ended up wandering into a PostgreSQL talk on how “wait events” can be used for troubleshooting performance, and I had a déjà vu moment because only yesterday I had run across the old Worklog for MySQL’s PERFORMANCE_SCHEMA which blames credits me for suggesting that’s what the name of the schema should be. It was yet another random “plate of shrimp” moment that has been happening with frequency as of late.
Then I attended a workshop from the Kubernetes Community Day track on using Argo CD to put the OpenGitOps principles into practice. While I have been using Docker for a while, I haven’t really played around with Kubernetes or other container automation tools, so I figured this might be a good way to start learning more. Unfortunately, the hands-on workshop part of the session didn’t actually work due to some problem with the training environment from the sponsoring company, which kind of helped reinforce my instinct that a lot of these tools still have a lot of sharp edges. The concept sounds great, though.
Finally, I popped back over to the PostgreSQL track for their (apparently popular) “Ask Me Anything” session with some of the prominent community members and core developers that were in attendance. I was reminded today that the PostgreSQL project doesn’t have a bug tracker aside from their mailing list archive. I remembered writing about this before, and it turns out that was in 2008. (No shade intended that they don’t have one, it seems to be working out okay.)
That was the day. I really don’t want to seem like I am passing any judgement on anything because I know that putting on an event like this is tremendously difficult, and while there is an impressive line-up of sponsors this is clearly a community-driven and focused event. I was disappointed by how old, white, and male the crowd seemed to be (fully acknowledging that’s my demographic), and I’ll be interested to see if that holds true for the whole run or if this an outlier day because it was more workshop-oriented and the expo floor wasn’t open.
scat is scatter-brained
while i folded all of the website/ecommerce parts of scat into the same repository as the point-of-sale system itself, it doesn’t really work out of the box and it is because of the odd way in which we run it for our store. the website used to be a separate application that was called ordure, so there’s a little legacy of that in some class names. i still think of the point-of-sale side as “scat” and the website side as “ordure”.
the point-of-sale system itself runs on a server here at the store (a dell poweredge t30), but our website runs on a virtual server hosted by linode. they run semi-independently, and they’re on a shared tailscale network.
ordure calls back to scat for user and gift card information, to send SMS messages, and to get shipment tracking information. so if the store is off-line, it mostly works and customers can still place orders. (but things will go wrong if they try to log in or use gift cards.)
there are scheduled jobs on the scat side that:
- push a file of the current inventory and pricing (every minute)
- pull new user signups (every minute)
- check for new completed orders and pull them over (every minute)
- push the product catalog and web content if a flag was set (checked every minute)
- push updated google/facebook/pinterest data feeds (daily)
- send out abandoned cart emails (daily)
so ordure has a copy of scat’s catalog data that only gets updated on demand but does get a slightly-delayed update of pricing and inventory levels. the catalog data gets transferred using ssh and mysqldump. (basically: it get dumped, copied over, loaded into a staging database, and a generated 'rename table' query swaps the tables with the current database, and the old tables get dropped so the staging area is clear for next time.)
not all of this is reflected within the scat code repository, and this post is just sort of my thinking through out loud where it has ended up. part of the reason for this setup is that the store used to have a janky DSL connection so i was minimizing any dependencies on both sides being available for the other to work.
as a side note, all of the images used in the catalog are stored in a backblaze b2 bucket and we use gumlet to do image optimizing, resizing, etc. when we add images to our catalog, it can be done by pulling from an external URL and the scat side actually calls out to the ordure side to do that work because when we were on that crappy DSL connection, pulling and pushing large images through that pipe was painful.
stable and well-understood technologies
AddyOsmani.com - Stick to boring architecture for as long as possible
Prioritize delivering value by initially leaning on stable and well-understood technologies.
i appreciate this sentiment. it is a little funny to me that what i can claim the most expertise in would probably be considered some of the most stable and well-understood technologies out there right now, but i have been working with them since they were neither. perhaps i have crossed from where as long as possible becomes too long, at least as far as employability is concerned.
siamang: a web-based command-line client for mysql
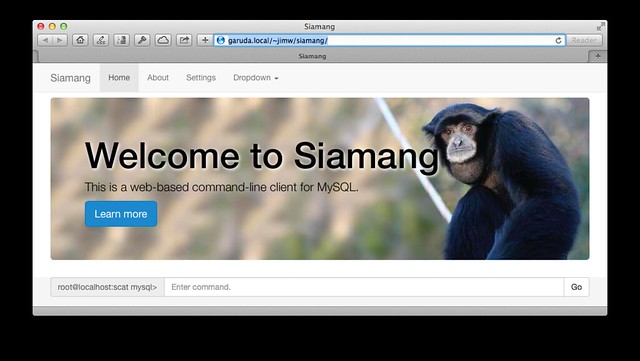
because i have many more important things to be doing, i procrastinated by whipping up a little web-based command-line client for mysql. what does that mean? you load the webpage, start typing in sql commands, and it presents the results to you. it is just a weekend hack at this point, and has a lot of rough edges. it does have some cool features, though, like a persistent command-line history using Web Storage.
probably the biggest limitation is because it not maintaining a persistent connection on the backend, you can’t use variables, temporary tables or transactions.
it was really born because i was getting frustrated running queries using the command-line client and having the ASCII table look all wonky because it was too big for my terminal screen. html makes that pretty much a non-issue. it is also tablet-friendly.
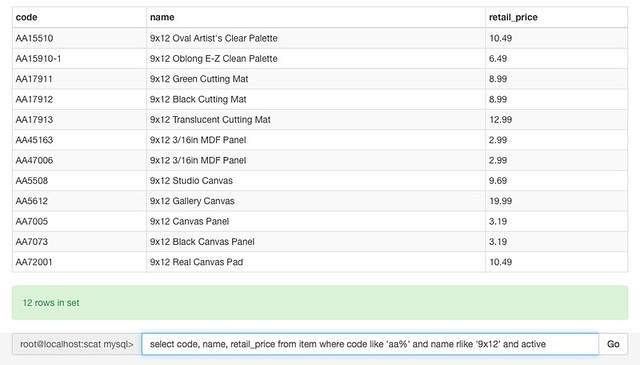
it was also an excuse to play with a few things i was interested in, like knockout. the whole thing is under 400 lines of code/html right now, but by leveraging bootstrap and knockout, it actually looks pretty polished and functional.
the name comes from a type of gibbon, which seemed to be unused in the software world.
you can find the source on github.
banker’s round for mysql
for some reason, nobody has ever exposed the different rounding methods via mysql’s built-in ROUND() function, so if you want something different, you need to add it via a stored function. the function below is based on the T-SQL version here.
CREATE FUNCTION ROUND_TO_EVEN(val DECIMAL(32,16), places INT)
RETURNS DECIMAL(32,16)
BEGIN
RETURN IF(ABS(val - TRUNCATE(val, places)) * POWER(10, places + 1) = 5
AND NOT CONVERT(TRUNCATE(ABS(val) * POWER(10, places), 0),
UNSIGNED) % 2 = 1,
TRUNCATE(val, places), ROUND(val, places));
END;
use at your own risk. there may be edge conditions where this fails. but this matches up with the python and postgres based system i was crunching data from, except in cases where that system gets it wrong for some reason.
one thing you might notice is that it does not use any string-handling functions like the other “correct” solution floating around out there.
i have other affairs to attend to
my last day with oracle (formerly sun, formerly mysql), today, came a little over eight years after my first.
on to the next thing.
how open is drizzle?
one piece of jay’s advice to mysql got me thinking about something that bugs me about drizzle development. jay said:
Make all decisions open and transparent: For the non-maintenance team, make a policy that all decisions about the kernel design be done in an open forum, with the community able to participate in the discussion. Have stewards that are willing to negotiate the design decisions with the community and do everything in a transparent manner.
since jay is one of the key lieutenants in the drizzle effort, it only seems to fair to put them up against that standard. one thing i have noticed is that there is relatively little discussion on the drizzle mailing list about all the coding that is going on. the latest discussions mostly seem to be flypaper for standards wonkery and taking shots at mysql.
meanwhile, you have big refactorings of code like mark atwood’s plugin-ization of several features that seem to just go into the code without any discussion of the design or implementation.
maybe all the discussion is happening on the irc channel, but that is not a great way to get much of the potential community involved. how much of it is happening off-line? maybe more than the core drizzle developers realize, or would care to admit.
an observer of his own legacy
one of the questionable habits i picked up in the run-up to the election is reading andrew sullivan’s blog at the atlantic. his thoughts about the recent interview with lame-duck president bush and how president bush seemed unable to take any responsibility for his own role for the failings of his presidency reminded me of monty’s thoughts on 5.1 being declared “generally available.”
work work work
was it really almost a year ago that i mentioned that my focus would be shifting from connector/odbc to libmysql? time certainly flies.
after what now seems much too long, i can say that we have carved out libmysql from the server source code, rebuilt its build system (using cmake), and are gearing up for an alpha release. the code is on launchpad, and it builds on all the platforms that the mysql server does. we have a build system set up that runs what scant tests we have on all of the platforms, and the big thing to work one before release is making more tests.
because this source is derived from the 6.0 server code, it has at least one big flaw that needs to get addressed — if you try to use utf-8, it uses the new 4-byte utf-8 supported in 6.0 even when talking to pre-6.0 servers, which then fails and falls back to latin1.
besides fixing that problem, our plan is to not make any large changes in connector/c (libmysql) for its first solo release. so the time from the first alpha release to the first “generally available” release should be small.
boring from another continent

as celia wrote earlier, we are in riga, latvia for a meeting of the mysql developers. she is holed up in the hotel room working on a screenplay (or maybe in the atrium where the wifi is better), and i am in a presentation about blogging.
celia already posted pictures from our excursion day on sunday (the day we didn’t sit around in the meeting rooms at the hotel). i took some video which i will figure out how to deal with once we are back home.
need anything dampened?
drizzle is an interesting new development in the mysql landscape. brian aker, who came along to sun microsystems in the acquisition but is actually now part of sun labs, not the database group, has taken the mysql server and started to strip it down to the bare metal. he isn’t working alone, of course, but has picked up some contributors during the stealthy period before they announced it at oscon on tuesday.
if you were paying attention the other day, you may have dug around my launchpad code page and noticed that i had a branch of drizzle where i was applying some fixes to make it build on mac os x. that should be merged into the main tree soon, so that branch will soon be retired. i’m not sure what i might try to do next.
drizzle isn’t something i am working on officially, but i can’t help but try to push things into some directions that i think would be fruitful. i certainly feel like i have a better shot of shifting its inertia than that of the mysql server.
how to fix eleven bugs in mysql 5.1
my “mysql client fixes” branch on launchpad contains fixes for eleven bugs (nine of them reported on bugs.mysql.com).
don’t get too excited — these are all the lowest priority-level bugs, mostly typos in comments and documentation.
now i have to figure out the latest process for actually getting these changes into the official tree. there are different policies around how and when to push to trees since i was last doing any server development. from someone who is partially outside, it all seems very tedious and designed to make it impossible to fix anything. process gone bad.
the mysql server isn’t going to get the benefits of using a good, open-source distributed revision control system unless it stops
my mac essentials
whenever i see somebody’s list of essential mac applications, i am always a little surprised at how little overlap it has for me. now that i’ve mostly switched over the new macbook pro, here’s the list of applications that i have installed:
- acorn ($50): this is a nifty little image editing application. in the last few days, i have been using it to mock up shelving layouts for the store.
- bzr (free): this is the distributed version control system of choice at mysql these days.
- busysync: it would be nice to keep my google calender and ical in sync. after giving spanning sync a try for a bit, i am giving this a try as an alternative.
- delivery status: this dashboard widget is great for tracking the way-too-many packages that i get from amazon and other places.
- google notifier (no cost): now that i have switched almost entirely to using gmail, this is useful to let me know when i have new mail.
- linkinus ($20): i use this irc client for accessing the company chat server to connect with my mysql coworkers.
- menucalendarclock for ical (no cost or $20 for more features): i like this replacement for the date/time display in the upper-right of the menu bar, which drops down a full calendar, including upcoming ical events.
- myob accountedge ($300): this is for doing the books for the store and gallery.
- mysql (free): i have the standard mysql server package installed for testing.
- twitteriffic (ad-supported or $15): this is a not-too-obtrusive way of participating in twitter nonsense.
- virtualbox (free): i used parallels on my last machine, but i figured i would give sun’s own virtualization technology a spin. i use it to run a windows xp image for development using the microsoft toolchain and for accessing sun’s vpn.
- xcode (no cost): i don’t really use xcode itself, just many of the unix development tools that come along with it.
of the bundled software, i regularly use address book, ical, iphoto, itunes, mail (for my sun/mysql email), preview, safari, and terminal. and i use time machine, but i hope i don’t have to regularly use it.
building c/odbc 5.1 on mac os x
to build connector/odbc 5.1 on mac os x leopard, the first thing you will need is xcode. then you will want to install a recent version of mysql (5.0 or 5.1, or even 6.0 if you are feeling adventurous).
to be able to build the gui setup library, you will need to install qt, but i have found it easiest to work with qt3, not the latest qt4. you can download the last release of that from trolltech’s ftp server — the file is called qt-mac-free-3.3.8.tar.gz. you will need to apply this patch to allow it to compile on leopard. i configure it with some options to eliminate stuff i don’t care about, and to build statically:
./configure -no-tablet -no-accessibility -no-cups -thread -static
with those prerequisites met, you can download the source for connector/odbc (using the release packages or svn for now, and we will migrate to bzr soon). i build with the gui enabled and with debugging symbols and no optimization:
./configure --with-qt-dir=/path/to/qt-mac-free-3.3.8 \ --with-extra-xlibs="-framework Carbon -framework QuickTime -lz" \ --enable-dmlink --with-debug CFLAGS="-O0 -g"
that should be enough to get the driver compiled. the test suite should mostly pass — there is one test in the my_basics suite that fails because of bugs in the iODBC implementation of SQLCancel, which i reported to them last november.
there is also one other test that fails right now, but we are working on that. it is a test for a workaround for a server bug, and it’s not clear whether the test case needs to be updated for the unicode-aware connector/odbc 5.1, or if the fix we applied in connector/odbc 3.51 didn’t get merged correctly into the 5.1 tree.
bug tracking and code review
i was going to write some reactions to an observation that postgresql has no bug tracker and its discussion last week, but lost the spark and abandoned the post after a few days. but today i ran across a quote from linus torvalds that neatly sums up my thoughts:
We’ve always had some pending/unresolved issues, and I think that as our tracking gets better, there’s likely to be more of them. A number of bug-reports are either hard to reproduce (often including from the reporter) or end up without updates etc.
before there was a bug tracking system for mysql, there was a claim that all bugs were fixed in each release (or documented), and there has been a lot of pain in seeing how well that sort of claim stacks up against a actual growing repository of bug reports. if the postgresql project were to adopt a bug-tracking system, i am certain that they would find the same issue. before long, they would be planning bug triage days just like every other project with a bug-tracking system seems destined to do.
another good email from linus about these issues was pointed out by a coworker, but this part in particular caught my eye:
Same goes for “we should all just spend time looking at each others patches and trying to find bugs in them.” That’s not a solution, that’s a drug-induced dream you’re living in. And again, if I want to discuss dreams, I’d rather talk about my purple guy, and the bad things he does to the hedgehog that lives next door.
the procedure at mysql for code reviews is that either two other developers must review the patch, or one of an elite group of developers who are trusted to make single reviews. then the developer can push their changes into their team trees, taking care to have merged the changes correctly in anywhere from one to four versions (4.1 and up).
this is a huge amount of friction, and is one of the most significant problems causing pain for mysql development. two reviewers is just too high of a bar for most patches, and having the rule makes the reviews rote and less useful. there is also an unreasonable amount of distrust being displayed by this procedure, that says that developers can’t be trusted to ask for help when they are unsure, but should feel free to make the occasional mistake by pushing something that isn’t quite right.
i wonder if we could be taking better lessons from linux’s hierarchical development model, with the pulling of code up through lieutenants to a single main repository, rather than the existing model that involves every developer moving their own stones up the pyramid. it would require some developers (more senior ones, presumably) to spend more of their time doing code management as opposed to actual coding.
monty is not particularly happy with the state of development of his brainchild now. would he be happier if he were in a linus-like role of rolling up patches and managing releases?
i wish had the patience to write at less length and greater coherence about this.
connector/odbc 3.51.25 and 5.1.4
connector/odbc 3.51.25 and 5.1.4 were released today. the new 5.1 release has been deemed “generally available,” which is our really ridiculous term for a non-alpha/beta/rc release.
it was the day for the connectors team to do releases — previews of connector/openoffice.org and pdo_mysqlnd made it out before us, and i believe that a connector/net release is in the wings.
connector/odbc 5.1.3 (release candidate!)
yeah, it is all odbc, all the time here, it seems. that is just because i can’t write about the really exciting stuff. soon!
that is not to say that releasing mysql connector/odbc 5.1.3-rc is not a huge milestone! it took us a while to get there, but we finally have a unicode-aware odbc driver that is, in our opinions, production-ready. now we just need some community feedback to find out if we are right. there are a few minor issues we know about already, but the impact of those is generally small enough that the majority of folks should not have any problems.
connector/odbc 3.51.24
the march of progress continues, with the release of mysql connector/odbc 3.51.24. we are down to 33 bugs, most of which will not get fixed further 3.51 releases, but will be fixed in 5.1 or later. i think the two remaining issues we might fix in 3.51 are the crashes of the setup library on mac os x (which may just require a 10.5 build) and bug #12805.
iodbc and mac os x problems
working with the iodbc driver manager on mac os x has been a frustration on two fronts.
first, the installer api functions provided by iodbc constantly set the configuration mode to ODBC_BOTH_DSN, which means you have to keep resetting it to the correct value after nearly every installer api call. this problem is platform-agnostic — the iodbc code is just plain wrong.
second, when called from the odbc administrator application on mac os x, any failures that the driver reports or passes through from the installer api in registering the driver are ignored, and the application instead uses a generic prompt for dsn configuration.
so even with the first problem fixed, the second problem has led to a lot of tail-chasing until i discovered that the odbc administrator application only obtains enough privileges to write to /Library/ODBC as a member of the admin group, not as the root user. because the connector/odbc installer was trying to be helpful in only creating the /Library/ODBC/*.ini files with root-writable permissions, it was running straight into the second problem.
this is all related to bug #31495 filed against mysql connector/odbc.
let the sun shine in
i completed all the paperwork to accept my new position at sun today. now i just need to drop it off at a ups dropbox or have ups pick it up. at least they didn’t ask me to fax anything.
for a hardware company trying to become a software company, you would think the process of “onboarding” would not involve writing your address on a half-dozen different forms.
i will be a “member of the technical staff 4 - software.”
yeah, they say that they are working on updating the titles and such for everyone.
don’t ask too many questions
chyrp is a nice looking piece of blog software. individual posts can have different styles, something it borrowed from the hosted tumblr service. i was interested to read about “the sql query massacre of january 19th, 2008” but the numbers gave me pause — 21 queries to generate the index page? that is down from an astounding 116, but that still seems ridiculous to me.
the number of queries to generate the index of this site? two. one of them is SET NAMES utf8. i could see boosting that to three or four if i moved some things like the list of links in the sidebar into the database, or added archive links. call it five if i had user accounts.
but right now, the number of queries used to load the index page on a chyrp site grows with the number of posts displayed on the front page. not only that, it grows by two times the number of posts on the front page.
chyrp could use a security audit, too.
connector/odbc 5.1.2
connector/odbc 5.1.2 was released today. this will probably be the last beta. we have gone back and triaged all of the bugs filed against connector/odbc, and have identified a few bugs that we have to fix before we will release a release candidate, but overall the trend of bugs is very encouraging. there are only a handful of bugs filed specifically against 5.1, and the total number of connector/odbc bugs is down to under 60.
what is 10% of php worth?
i am listed as one of the ten members of the php group. most of the php source code says it is copyright “the php group” (except for the zend engine stuff). the much-debated contributor license agreement for PDO2 involves the php group.
could i assign whatever rights (and responsibilities) my membership in the php group represents to someone else? how much should i try to get for it? i mean, if mysql was worth $1 billion....
i am still disappointed that a way of evolving the membership of the php group was never established.
new responsibility
while we start to wind up development of connector/odbc 5.1, i will also be taking on responsibility for libmysql, the c library that defines the client interface to mysql, and the mysql command-line utilities. there are about 120 active bugs in those areas right now, so the first task will be getting that down to a more manageable number.
after that, the field will open up for new development. i know that an asynchronous interface to libmysql is on some people’s wishlist, and there are other areas where i think that libmysql could be cleaned up in general.
but the idea that i think is the most exciting is to build a scripting language into the mysql command-line client, such as lua. this would allow us to rewrite many of the utility scripts and perhaps even other command-line clients (like mysqldump) in lua, so they would be easier to work with and more naturally cross-platform.
i should be careful to note that this does not mean that we are abandoning connector/odbc development (again). it is just that 5.1 has been a huge leap forward in closing most of the gaps in its functionality, and the remaining features are both not numerous and not that widely used.
some things to be excited about
still wrapping my head around this whole sun thing, but i have to say that i am a little excited about some of what i see in sun’s explanation of their benefit package. above and beyond what mysql offers now, there is matching on the 401(k), a stock purchase program, and charitable contribution matching. there is also a tuition reimbursement program.
it does look like i’ll be losing some days off, or at least the flexibility on them (more holidays, less vacation time).
and there is a new employee referral bonus. so if you want to work for sun (or as i suspect mårten will be referring to it, mysql), wait a few months and let me refer you!
what it means

you may have heard that sun has agreed to acquire mysql. what does that mean for me? that i still really wish i wasn’t in orlando, and was at home with my wife and puppy.
connector/odbc 3.51.23
we usually try to avoid doing releases on friday, but we had been trying to release mysql connector/odbc 3.51.23 for a while now, and if it didn’t happen today, there was a good chance it wouldn’t happen for a few more weeks. this release just contains a few bug fixes, but we have gotten the bug count down to 60. one of the things i hope we can accomplish at our big orlando meeting is doing some triage on those remaining bugs.
connector/odbc 5.1.1 (beta!)
mysql connector/odbc 5.1.1-beta is available.
we didn’t implement all of the features in our original plan, but we decided to close out 5.1 to new features so that we could work on getting it to a production (GA) release as soon as possible.
5.1 has it’s share of bugs still, but we have tackled the most serious ones, and now that we are done with features (for the time being) we can focus on making the GA release shine.
now the race is on to see who gets out a 5.1 GA release first — the server or connector/odbc!
mac os x programming help needed
one of the features we had planned for mysql connector/odbc 5.1 is native setup libraries for the major platforms. we have the microsoft windows version going, and some code to get us going on linux/unix (using gtk instead of qt), but our gui team is too busy to get us started on a native mac os x version.
anyone want to pitch in by showing us how to get a basic dialog window to pop up based on a c library call? i think we will be able to customize it from there, but i am just unfamiliar enough with mac os x gui programming that i have a feeling it would take a long time for me to get that going.
connector/odbc 3.51.22
mysql connector/odbc 3.51.22 is available, still keeping to that mostly-monthly schedule. there has actually been an slight increase in the bug count to a little over 70. we went back through all of the bugs filed against the now-defunct 5.0 version, and that turned up some that still appeared in 3.51.
the next release of the 5.1 branch is still imminent. it has taken a little longer than planned to get the new windows setup library integrated.
a mountain so high
greg knauss wrote “wide vs. deep” to explain why he is not happy being management, and what he thinks the difference is between people well-suited to management and those that are not.
i don’t know if i agree with his explanation, but i think it is very important for organizations to realize that there cannot be only one career path that leads up through management. to mysql’s credit, the recent work that was done to standardize our job titles and the path up the ranks acknowledges this, and there is a non-management path for developers. i don’t think we are quite where we need to be in terms of divorcing technical leadership from resource management, but we are getting there.
and mysql is hiring for all sorts of positions.
how to win a nobel prize
khoi vinh’s piece on the poor user-interface design of enterprise software was my latest forward to the business-intelligence list. this is something that has bothered me about vertical-market software for a long time, and i have mentioned it in passing before.
i think it stems from a certain combination of ignorance and laziness. i say “ignorance” because vertical-market software often comes from the hands of domain experts who just sort of cobble something together because they don’t really know better. the “laziness” comes in when they don’t recognize that they have really transitioned to being in the software business, and they don’t learn that business, and the vertical market they are addressing is just so happy to have something that they don’t demand something that software experts might develop.
and there’s the ongoing curse of upgrade-itis. from this ask metafilter discussion about final draft, the leading screenwriting software, you can read how it is getting more overburdened with features that fewer people use. that will likely be ongoing until some new piece of screenwriting software (scrivener?) hits a sweet spot of features that satisfies enough people that it will become the top dog, and then eventually get bloated with features in the ongoing quest for upgrade revenue.
the person who figures out how to get people to buy software upgrades that simply get rid of features that turned out to be not very useful will deserve some sort of nobel prize.
but enough about me, what do you think of me?
in his infoworld blog, zack urlocker (vp products at mysql) passes on a good link about smaller software teams. and says very kind things about me, since he read the article after i posted it to our internal business-intelligence list. i used to report directly to zack, but i have managed to shoehorn in three other people between us on the orgchart since then.
that business-intelligence list is kind of a funny beast. it is mostly industry news (who bought who), with some interesting mentions of mysql in the press and blogs, and my ongoing implicit criticism of our development processes. it would make a pretty good blog. i should at least start posting the things i have been sending to the list.
expensive parts
friendly note: do not go to the apple store at the glendale galleria, at least for a month or two. between the ongoing construction in the parking structure which makes it a bear to get in and out of, and the super-small space the apple store is in while they remodel their usual location, it is not a particularly pleasant experience. luckily, they called my name about ten minutes after my appointment was scheduled. the store was jam-packed, especially for the middle of wednesday afternoon.
the genius made a quick verdict of fried logic board for the mac mini. when he looked up the price to repair it, it came up as $612. which is just barely less than a new mac mini would be. now it is up to my boss (or his boss, or his boss, or his boss, or maybe someone else) to decide if replacing the computer is an acceptable expense.
after giving me the bad news on the computer, the genius hooked up the monitor that i thought had a fried power supply, and it turns out that it works just fine. whew!
we grabbed a late lunch at the oinkster in eagle rock after leaving the apple store (and i dragged celia out of the pet store next door). their bbq pork sandwich is so tasty. and so is the ube shake.
connector/odbc 3.51.21
after eight releases, we have gone from over 150 open bugs to under 70 bugs.
one of the really old bugs we are still looking at is how identifiers that are reserved words (or have non-alphanumeric characters) are handled from ado. as far as we can tell, the driver is doing everything correctly, and it is ado that is failing to properly quote the identifiers, but we have gotten some developers at microsoft involved in tracking the problem from that end.
just today there was a new bug filed about using the driver with visual basic 6, which was itself released in 1998. i am going to have to build a vm image with that installed so i can do some testing.
the next release of the new 5.1 branch should be out later this week. we will probably limit the scope of new features we are going to implement in 5.1 so that we can get unicode support and the other already-implemented features out there as a beta (and then production/ga) release sooner.
willkommen zum oktoberfest

after the heidelberg mysql developers meeting, we got on to the serious business of oktoberfest in munich. one of my coworkers had secured tables inside the hippodrom for two of the days, and we took full advantage of that.
the weather was not very good while we were in munich, and we were definitely starting to feel the end of the trip, so we did not explore munich outside of the oktoberfest grounds. that just means we will have to go back another time.
this time my pictures actually have some people in them. and lots of beer.
hardly working
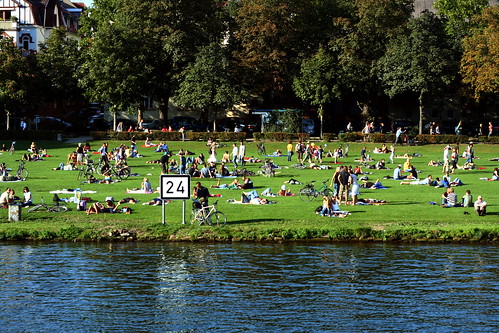
this is the mysql developers working hard at our developer conference in heidelberg, germany.
okay, not really. this is just a shot of a park on the shores of the neckar river in heidelberg, germany, taken while we were on a boat back from our day-off excursion to the german raptor research centre.
the whole set of photos has more of heidelberg, and some of the birds from the research centre. but no shots of any developers. you will have to wait for the oktoberfest pictures for those.
my wife celia also posted her pictures from heidelberg and pictures from oktoberfest.
connector/odbc 3.51.20 and 5.1.0
another month, another release of connector/odbc 3.51. there’s not a lot of bug fixes in this one, but we did manage to get the bug count under 80 bugs.
the reason there were fewer bug fixes in the release of 3.51.20 (other than there being fewer bugs to fix) was that we have been hard at work on connector/odbc 5.1.0, which builds on the 3.51 foundation to bring new functionality like unicode and descriptor support. there are more features planned, and you can see the release announcement for details. i hope that we’ll be able to keep on releasing new versions of 3.51 and 5.1 on a monthly basis.
connector/odbc 5.0 has met the same fate as the aborted 3.52 and 3.53 releases. it was an ambitious ground-up rewrite of the driver, but once we had put renewed efforts into getting the 3.51 code into better shape, it became clear that doing the same for a completely different code-base made little sense. we are going to be cherry-picking some of the 5.0 code for some of the new features.
i am sorry that we have been secretive about what was up with the future of 5.0, but we decided it was better to not talk about what was happening until we were confident about the decision to kill it.
connector/odbc 3.51.19
we managed to let a pretty significant regression sneak through in 3.51.18, so we’ve turned out a quick release of mysql connector/odbc 3.51.19. sorry for the hassle.
connector/odbc 3.51.18
we were able to get out this month’s connector/odbc release a little earlier in the month than usual. one reason we made the release earlier was to get a replacement for last month’s 3.51.17 out there, because that release had an unfortunate bug that caused problems when working with many odbc applications, like microsoft access.
we were also able to get under 90 bugs by fixing a number of other bugs, and working through more of the old bugs and figuring out that they were either already solved or otherwise no longer relevant.
the other reason to get this out earlier in the month has to do with a project that should see some more daylight by the end of the month. more on that when the time comes.
connector/odbc 3.51.17
another month, another mysql connector/odbc release. it has almost become a trend. we only chipped it down to about 124 bugs this time, about a half-dozen less than last time. but we’re going back and re-evaluating some the open bugs now.
we didn’t manage to get windows x64 packaged up this time, but we might slip out a 3.51.17 package for that platform before the next full release. part of the problem in getting it together in time for this release was that odbc on win64 appears rather half-baked, and we couldn’t find much in the way of applications to test with it.
now i’m hip-deep in making sure that the way we calculate the various column lengths that you can retrieve from odbc are correct. in many cases they are not, but the msdn odbc documentation is wonderfully imprecise on what lengths are meant to be returned for many of these. and it sometimes appears to contradict some of the ibm db2 odbc documentation.
independence day for code
as i’ve been threatening to do for quite some time, i’ve finally made the source code for bugs.mysql.com available. it is not the prettiest code, and there’s still all sorts of hard-coded company-specific stuff in there. but it is free code, so stop complaining.
it is available as a bazaar repository at http://bugs.mysql.com/bzr/. i have not yet set up any sort of fancy web view, or mirrored it to launchpad.
i plan to do the same for the lists.mysql.com code some day. one limiting factor now is that machine only has python 2.3 on it, and bazaar needs python 2.4.
my five mysql wishes
jay pipes started with his five mysql wishes, and others have chimed in. i guess i may as well take a whack at it.
connect by. yeah, yeah. it’s not standard. i don’t care.- expose character-set conversions in the client library. all the code to convert between all of the character sets understood by the server is there, there’s just no public interface to it.
- online backup. it’s in progress, but this will make things so much better in so many ways. we could actually have reliable backups of bugs.mysql.com. and it’s going to make starting up new slaves so much easier in replication.
- re-learn how to ship software. the long release cycles of 5.0 and 5.1 have been pretty ridiculous, and i’m sure we can find a better way to add features without having to slog through months of bug-fixing to get a release to production quality. it is frustrating to ask for new features and have the fear that there won’t be a production release that includes them for another couple of years.
- fix planet mysql to handle utf-8. seriously, guys, it’s not that hard.
connector/odbc 3.51.16
it’s another month, so time for another connector/odbc release.
there’s already three bug fixes that have been committed to the repository for the next release, and the changes to support building on windows x64 should land soon.
we’re down to about 130 open bugs, about 20 less than the last release. some of those were newly fixed, and some were closed because they duplicated earlier problems that had already been fixed. this release does close another bug that is nearly three years old.
one of the things i hope to get fixed for the next release is being able to specify the default character set for the connection. you can’t do this now, so when developers try to use a different default character set like big5, problems show up in how parameters are escaped. this shouldn’t be hard to do, but it will involve adding another widget to our gui configuration, which i haven’t really had to do very much with up until now.
rambling about work
sorry for things being so boring around here. i’ve been grinding away at bugs at work. after gaining some ground on bugs in connector/odbc, i’m being reassigned to help out with some server bugs again, at least part-time.
fixing bugs in c/odbc is an adventure. the code base bears the scars of several different developers of varying levels of cleverness and somewhat conflicting coding styles. but now that the test suite is in shape, it is easier (and safer) to do some more mechanical transformations to undo some of the damage.
one problem with tackling bugs in an odbc driver is that a lot of the reports involve third-party applications like microsoft access or crystal reports, or development tools like delphi that we don’t have as much expertise in. the initial reports often don’t include all of the information we need to be able to reproduce the bug.
this can be frustrating both for us and the reporters — we just don’t have enough people looking at c/odbc bugs to play around with every application to figure out exactly how to reproduce bugs that are reported, and often the problem seems blindingly obvious when you’re the one who runs across it. i think that most of the time we get it under control, but there have been a few times when this frustration has taken things in the wrong direction.
connector/odbc 3.51.15
this time it only took two months since the last release — mysql connector/odbc 3.51.15 is now available. there aren’t a lot of bugs fixed in this release, compared to the 150 or so open bugs, but it is nice when you get to close a bug that is nearly three years old.
i’m not sure when the next release will happen, but i already have one patch pending.
style="design: prettier"
i finally got tired of the index pages on the mysql mailing lists looking like ezmlm-cgi, so i cribbed some design from the perl mailing lists and now the by-thread index pages include who participated in a thread. i didn’t steal the pagination of busy months. yet.
i need to package up more of the bits of code driving the mysql mailing lists. there are some quirks, but i like the way it all fits together.
i also need to put in the few hours it would take to make it possible to post to the lists from the web interface.
angry programming
mysql doesn’t have quite the number of fancy internal applications that you might suspect, and i got frustrated when the company started to roll out a system of monthly time-off reports based on emailing around an excel spreadsheet. (to add icing to that cake, they kept sending out the excel sheet with password protection!)
last friday, i spent an afternoon cooking up this little proof-of-concept application that tracked the same information as the spreadsheet, but in tasty web format, with some ajax goodness (courtesy of prototype).
as it turns out, there was an official company tool for doing this that was in the works, but they hadn’t bothered to let anyone know it was imminent. i’m told it is sox-compliant and configurable six ways to sunday. i haven’t seen it yet.
so my meager efforts did not go to waste, i just spent another half hour to make this a standalone demo (rather than tying into our internal personnel database). perhaps someone else can find some use for it, or take some inspiration from it.
here’s the simple workflow for the application:
- employee clicks on days they took off in a month.
- employee clicks button to get month approved, which sends email to boss.
- boss reads email and follows link to view the report online.
- boss clicks the button to approve the report, which sends mail to the employee and the finance department.
- the finance department does whatever it does with the data. the employee can no longer change it.
obviously that’s not quite all you would want for a fully-functional application, but it is most of the way there. i think it’s already better than the system that involved emailing an excel spreadsheet around.
jobs at mysql
mysql has quite a few open job listings. some positions of note: web developer, support engineer, maintenance developer, qa engineer, and performance architect. all of these positions are available world-wide, so you get to work from home. some of the other jobs from the full list are location-specific.
if you mention that i referred you for some of these positions and are then hired, i get some sort of referral bonus.
another connector/odbc release — finally
a mere seventeen months since the last release, we finally managed to release version 3.51.14 of connector/odbc. while much of the development energy around connector/odbc is going into the rewrite from scratch, there’s a few of us that have been working on getting the old workhorse of 3.51 back into shape and releasable.
kent from the build team has constructed a new build tool that lets him crank out builds (and test them) on too many platforms, bogdan and tonci (and others) from the support team have really dug in and solved some annoying problems our customers have run across, and georg and i have been getting into the code and cleaning up some of the other issues. there were also a number of fixes from peter that had simply not been released yet.
there will probably be some embarrassing problems with this new release, but now we finally have the tools at hand to do a release without breaking the back of any one person, and we are getting more organized and disciplined about how we fix the bugs that remain.
backcountry programming
i’m back to doing some work on connector/odbc, fixing bugs in the “stable” version (otherwise known as 3.51.x). we have another project going that is a ground-up rewrite of the driver, but i’m not really involved with that.
the state of the stable version of the driver is pretty sad. i keep running into pockets of code that are truly frightening. my first big foray was a bug i reported when i was trying to get the test suite to run, and it basically entailed throwing out a function that made no sense and replacing it with code that has such niceties as comments.
as i’ve started into the catalog functions, starting from this ancient bug, i’m finding even more frightening (and untested) code.
my general goal is to leave things cleaner than i’ve found them, doing things as incrementally as i can. we’re going to be building out a richer test suite, which will be a tremendous help, both in getting the “stable” version of the driver into better shape, and proving the capabilities of the rewrite.
i know it has been a long time since the last connector/odbc 3.51 release — kent, one of the build team members, is working on scripting the building, testing, and packaging so that we can crank out builds more consistently and reliably. unfortunately, a lot of the magic incantations were lost as people moved on to other work or other companies. the days of connector/odbc being the neglected stepchild of mysql products may be coming to an end.
being known for being you
mike kruckenberg shared his observations from watching mysql source code commits, and jay pipes commented about this commit from antony curtis which had him excited. now that’s how open source is supposed to work, at least in part.
i replied to a later version of that commit to our internal developer list (and antony), pointing out that with just a little effort the comment would be more useful to people outside of the development team. “plugin server variables” doesn’t really do it justice, and “WL 2936” is useful to people who can access our internal task tracking tool, but does no good to people like mike.
the other reason it is good to engage the community like this is because it is very healthy for your own future. being able to point to the work i had done on open source and the networking that came from that have both been key factors in getting jobs for me. i’m sure it will be useful next time i am looking, too.
web sites are expensive?
reporting about david geffen’s apparent bid for the los angeles times, nikki finke says “He’ll ratchet up the Web site (even though he hates how prohibitively expensive it is to do that).”
prohibitively expensive? i guess there is still a lot of stupid money flowing into web properties. i’m in the wrong line of work.
a strange little side-note: mysql’s website gets more traffic than latimes.com, according to alexa.
joining activerecord with mysql 5
dhh committed a patch for activerecord to make it work with mysql 5 that was subsequently reverted because it broke things on postgres and sqlite.
obviously we’d like ruby on rails to work with mysql 5, but because there was no test case committed along with either of these changes, i don’t really know the root cause of the problem. dhh claims it is the changes that made mysql conform to the standard sql join syntax, but i can’t evaluate that because i can’t reproduce the problem.
any activerecord gurus want to point me in the right direction?
better out-of-the-box mysql support for ruby on rails
activerecord now supports mysql 4.1 (and later) out of the box whether you are using new or old-style passwords, because they applied my patch for handling the related protocol changes correctly.
(it’s not quite out-of-the-box yet — the fix will appear in the next major release of rails, i guess. it’s fixed in their repository.)
now if only the upstream developer would show signs of life, and get that fixed. i’d complain about that more, but there’s a lot of windows around here.
don’t bother paddling upstream
so turns out that the ruby on rails developers had already added 4.1 authentication support for their bundled version of ruby/mysql, but they’ve found the upstream maintainer as unresponsive as i have. their implementation wasn’t quite complete, so i’ve submitted a patch to round it out.
the version included with ruby on rails doesn’t include the test suite, though.
more ruby/mysql love
i’ve updated my patch for new-style mysql authentication for ruby/mysql, with a new test case for the change_user method (and support for same with new authentication).
i’ve even tested this against a 4.0 server, so i’m pretty sure i didn’t break anything.
new-style mysql authentication in pure ruby
ruby has two modules for connecting to mysql. one is called mysql/ruby and is built in top of the standard libmysqlclient c library. the other is called ruby/mysql and is pure ruby. the problem with the latter is that it is a from-scratch implementation of the mysql network protocol, and the authentication handshake changed in mysql 4.1.
but here is a patch to add support for new-style mysql authentication to ruby/mysql. it should also deal with the other protocol changes that came along at the same time. it doesn’t do anything to expose server-side prepared statements.
it is only lightly tested. in particular, i haven’t tried to connect to a pre-4.1 version of the server. it should still work, but it is entirely possible i screwed it up. i’m also still just learning ruby, so there are some ugly bits.
i think having more from-scratch implementations of the protocol is a good thing. there’s at least five — the server code itself (and client library), connector/j, connector/net, ruby/mysql, and Net::MySQL (perl). once we have these all collected into an integration test suite, the server developers will get much better feedback when they go off the reservation with the protocol.
where should i be lurking?
trying to find places where people talk about using python, ruby, and php with mysql has been a bit of a challenge.
the problem on the php side is that php forum on forums.mysql.com is so filled with pre-beginner-level questions that it’s barely worth it for me to spend my time digging through it.
for python, the python forum on forums.mysql.com is nearly a ghost town. the forums for the mysql-python project seem slightly active, but the sourceforge forum interface is just bad. (not that any web-based forum isn’t starting from a bad place.) the db-sig mail archives also have some interesting discussions.
for ruby, the ruby forum on forums.mysql.com is even quieter than the python one, and i haven’t found anywhere else.
another thing i’ll take a look at is apr_dbd_mysql, which is not part of the main apr-util repository because of licensing issues (ugh).
where else should i be looking?
more technobabble
working on the mysql bugs system filled the transition from me working on falcon to joining the connectors team, where i’ll be focusing on the connectivity for scripting languages.
my initial focus will be on python, ruby, and php. i haven’t figured out exactly what it is that i’ll be doing, but a likely candidate for my first big task will be building out the test suites for these so that they can eventually become part of our build verification process.
…and they never check out
right on schedule, i’m done with the pressing changes we wanted to make to the mysql bugs system. the most visible things (to non-mysql employees) are probably just the cleanup of the layout of the bug pages themselves, and the new public tagging interface. (with the requisite ajax-y goodness.)
under the hood, i’ve taken a machete to some of the more egregious bits of code. that’s not to say there isn’t a lot more that could be cleaned up, but it’s a start. now that i’ve cleaned up the bug reporting and editing forms, they’re ripe for merging.
based on the priorities set by the developement management team, i did less of the cleanup of the main bugs schema than i had originally planned, but things are in a state now that it should be easier to tackle those in the future.
my plan is to release this code publicly, but one of the things i need to do first is transition it out of bitkeeper and into another revision control system. probably bzr, but i really wish it supported per-file commit messages.
tasty dogfood
part of my focus for the next couple of weeks will be on rolling out some improvements to the mysql bugs system. the first step in doing that was to upgrade from mysql 4.1 to the latest mysql 5.1 beta, which turned out to be entirely painless.
the next step is going to be some database normalization and code refactoring. but because there are some other people who have written ad-hoc tools against the existing schema, i’ll be hiding the schema changes behind some views.
the first big schema change will be moving the categories from a bunch of hard-coded strings in the source code (and a varchar(32) field) to a table organized using the nested set model. that’s something i’ve been wanting to do for years.
i’m not wearing pants
just a few days before reports surfaced that hp would be cutting back on telecommuting, mysql was cited in an article about great teams because we operate without a headquarters. (not quite true, except relative to most companies.)
working from home is great for me, but i can understand how a boss with control issues couldn’t stomach it.
how i work
dave rosenberg has been doing a series of “how i work” interviews and asked for more submissions. here is mine.
what is your role? i believe my title is still maintenance engineer, but i’m now actually a proper server developer at mysql. right now i’m doing some falcon-related work, but i hope to get back to working on pluggable authentication and authorization soon.
what is your computer setup? my desktop is a mac mini (powerpc), hooked up to a 20" apple cinema display. my development box, which runs headless and i just access with ssh, is an amd64 running ubuntu. i also have a 12" powerbook that i use when on the road (which isn’t often). my plan is to replace the mac mini and powerbook with a new macbook pro at some point down the line. this site also runs off a colo server.
what desktop software applications do you use daily? when i am working, i’m always running safari, terminal, itunes (plus synergy classic), colloquy (irc client), and the stickies application. i also have antirsi running to remind me to take breaks. i use mutt, running on my colo server, for all of my email.
what websites do you visit every day? i have my own rss aggregator that i use for reading various news feeds, and it has a blo.gs-based sidebar that lets me know when the various weblogs i am interested in get updated. i read planet apache, planet php, planet perl, planet mysql, and planet intertwingly regularly.
what mobile device or cell phone do you use? i have a motorola razr, and i sync my address book over bluetooth. i recently started using bluephoneelite, which lets me send sms from my computer, and also pops up caller information when i get a call on my cell.
do you use im? i went back to using ichat after dabbling with adium, but now that my fiancée celia is working from my couch, i haven’t even had a need to keep ichat running.
do you use a voip phone? every once in a while i’ll fire up sjphone to use the company’s internal voip network, and i’ll fire up skype once in a while.
do you have a personal organization/time management theory? not really. i use the stickies application to keep track of what i’ve done this week, and my short to-do list for work. my incoming email gets sorted into three folders: personal, work, and the mysql mailing lists (i’m subscribed to all of them). i try to keep the personal and work inbox to under thirty messages (generally successfully — they currently have nine and ten, respecitively), and i flush out the mailing list inbox regularly. we have a couple of monthly calendars on the fridge to keep track of upcoming events.
anything else? the whole cult of “gettings things done” creeps me out.
i don’t like “better feed”
i finally saw someone make mention of the plugin that adds the load of awful crap to the end of some people’s blog entries which clutters things up on sites like planet mysql. it’s called “better feed.”
clearly, “better” is in the eye of the beholder. i find it to be an eyesore.
acronyms
tim bray coined MARS: it stands for “mysql + apache + ruby + solaris.” (get the shirt.)
bill de hóra proposed MADD: “mysql + apache + django + debian.”
when forwarding the above to an internal mailing list at mysql, i proposed MAUDE: “mysql + apache + ubuntu + django + eclipse.” the logo would be a picture of bea arthur, of course.
but mårten mickos, ceo of mysql, came up with MARTEN: “mysql + apache + ruby + tomcat + eclipse + nagios.”
or would that be åpache?
pictures from the mysql users conference
 i just took a few pictures, and only the three that i’ve tagged were worth sharing.
i just took a few pictures, and only the three that i’ve tagged were worth sharing.
but i like that i caught david in the act of doing what he seemingly does the most at conferences — taking a picture.
the conference was great, or at least the day of it that i attended was. it’s still on-going, and you can check out planet mysql for ongoing coverage.
slides from my talks at the mysql users conference 2006
short and simple: “embedding mysql” and “practical i18n with php and mysql.”
the i18n talk seemed to go over pretty well, and i only ran a few minutes short. the embedding talk is yet to come, and will run really, really short.
i would recommend the scale out panel instead.
no oscon for me
the o’reilly open source conference 2006 schedule is out, and i’m not on it. (i got my rejection letter yesterday.) here’s the talk i had proposed:
“22 Small Features in MySQL”
Did you know the mysql command-line client could save you from accidently nuking whole tables with errant DELETE statements? What about how the ability to change data being loaded using the LODA DATA statement that was added in MySQL 5.0?
In this session, we'll look at these and twenty (or more) small features of MySQL and its supporting programs. Some are old classics, and some are new additions to MySQL that you might not have noticed behind all the big new features.
oh well. after the upcoming mysql users conference, i think i’m doing with conference speaking. i just don’t enjoy it any more.
one month to go
 the mysql users conference 2006 is only a month away. i’m just going to be dropping in for one day to give two talks — “embedding mysql” and “practical i18n with php and mysql.”
the mysql users conference 2006 is only a month away. i’m just going to be dropping in for one day to give two talks — “embedding mysql” and “practical i18n with php and mysql.”
there is also a great lineup of other speakers, tutorials, and keynotes. i’m going to miss the keynote by mark shuttleworth, but i am looking forward to the keynote by the founder of rightnow.
oracle licensing too expensive for oracle community site
from this thread on the orafaq forum:
“There is no way we would be able to raise the money required to buy a commercial Oracle license.”
“I believe the XE edition is a max of 2gig. htmldb would be free for that, but by the time you add htmldb overhead and users, I gotta think this site has way way more data than what is left out of the starting 2gig. … Standard Edition One would be the next option, at 5 grand per proc.”
maybe oracle will toss a free license their way, but this is a great case study on how useless oracle’s free offerings really are. (to contrast, of course, mysql’s free offering is fully-featured, with no artificial limitations. same with other truly free databases like firebird or the open-source versions of postgresql.)
“we are the champions”
there’s a couple of more karaoke pictures in my photostream. sorry, no pictures of italian hookers.


mixed attention
 our morning are dominated by meetings with the whole development team, which can result in a range of attention being paid. this was taken while monty and patrik were briefing us on a project you’ll hear more about at the mysql users conference in april.
our morning are dominated by meetings with the whole development team, which can result in a range of attention being paid. this was taken while monty and patrik were briefing us on a project you’ll hear more about at the mysql users conference in april.
the camera on the table belongs to david axmark, our co-founder who is infamous for taking tons of pictures that nobody ever sees. (that’s also his laptop screen in the bottom corner, he is out of frame.)
mysql developer meeting, sorrento

the mysql developers are all gathered in sorrento, italy, to have the sorts of full-bandwidth discussions that only being close enough to exchange blows can catalyze.
this sort of view will be the norm for the next week as we gather in the hotel meeting rooms, but then i’ll get to spend a day on a tour of pompeii. i hope vesuvius won’t blow up.
the truth is out there
 i talked at scale 4x, and you can download the exciting slides. the picture is of future oracle employee and zend co-founder andi gutmans, and there are a few more pictures from the first day.
i talked at scale 4x, and you can download the exciting slides. the picture is of future oracle employee and zend co-founder andi gutmans, and there are a few more pictures from the first day.
(neither andi nor dave from sleepycat admitted to the imminent acquisitions of their companies by oracle.)
see the live show
i’ll be giving a talk about the latest mysql features at the southern california linux expo next month (out near lax), and then giving at least one talk (on embedded mysql) at the mysql users conference 2006 in april up in the bay area.
early admission for both conferences is still available. scale4x is $50 until january 16 (or less if you get your hands on a promotional code), the mysql users conference is $945 until march 6 (with various discounts available, like the 15% o’reilly conference alumni discount).
2005 in review: work edition
there are only a few hours left in my work year, so i did a little crunching to see what i accomplished this year. since i started the year with a new position on the maintenance team, there is really one major metric — how many bugs that were assigned to me are now closed. as of this instant, that’s 224. it will go up by another few when some additional fixes are documented. here is the search to see all of the server bugs i have closed. “server bugs” includes bugs in the command-line clients.
that works out very close to one bug per working day. whew!
of course, i’m just one step in the process. sergei golubchik is listed as the reviewer on over 300 of the bugs that were closed this year!
except all the others that have been tried
in an o’reilly network article, matthew b. doar asks, “bug trackers: do they all really suck?”
my answer would be yes, but i love tinkering with them anyway. we’re still using a hacked up version of the bugs.php.net code at bugs.mysql.com, despite periodic threats to move us over to bugzilla. some things that block the migration are that we’ve added various bits of workflow and bitkeeper integration into our bug tracker that someone will have to re-do for bugzilla, and someone will also have to figure out how to integrate it into the login infrastructure (and user database) for our websites.
meanwhile, i hack new features and fields into the existing bugs system whenever the need is strong enough.
α-bits
hot on the heels of the mysql 5.0 production release, the first mysql 5.1 alpha release is out. the major new features in the alpha are partitioning and the beginnings of the new plugin api (allowing for some cool full-text possibilities now, and even more to come in 5.1 and later versions). here’s the full announcement.
new to the database field
“Sleepycat employs a lot of database people with, like, 25 years of experience,” [Josh] Berkus [evangelism guy for PostgreSQL] said. “One problem MySQL has is that most database people working there are new to the database field.”
that is a laughable statement that simply demonstrates that josh has little insight into the breadth and depth of experience of the mysql development team. it includes a number of developers with long experience in the database industry and recognized experts in the database field. the jokers like me who just brought a non-database background to their jobs are not representative of the whole development team. i can understand why josh got it so wrong, though. those of us who came through the open-source community tend to be more visible in that community.
the quote comes from this eweek opinion piece by lisa vaas about how mysql may re-team with sleepycat. and this doesn’t mean that lisa is right, but the timing of her piece and this announcement from sleepycat about their latest version is pretty funny.
and if richard mason got taken out to the woodshed for what he said, it is probably because “replace” is the wrong word to use. un-factual, as one might say. and i can’t imagine it was a very unpleasant trip to the woodshed considering how well his european sales team has been doing.
like always, seeing something in the press about things you have first-hand knowledge about is a good way to remind you how wrong the press often is, and how skeptically you should treat it.
mysql is looking for a north american mysql community relations manager. quality assurance engineer is another position available, and there are more listed on the website.
funny characters are not ☢
sam ruby pulled a good quote on building in support for internationalization in web applications, which i agree is really important.
it is very annoying that i can’t use my flickr recent comments feed because the atom feed is broken due to bad utf-8 handling.
i’m thinking of doing another talk at the mysql conference next year about handling this sort of thing. there’s really no excuse for it. which makes it a little hard to do a 45-minute talk on — it’s so easy to get right!
numbers singly
the “generally available” (or production-ready) version of mysql 5.0 was officially released today, and kai voigt, one of the mysql trainers, has posted a sudoku solver written as an sql stored procedure. the solver was actually written by per-erik marten, the main implementor of mysql’s stored procedure support.
it’s probably not the best showcase of stored procedures, but it is a nifty little hack.
chicken little doesn’t come out until november 4.
mysql is looking to hire a community relations person in the united states.
oh, and the mysql users conference 2006 was announced, and the call for papers is out. the deadline for submissions is november 7.
blogging.la follows up on the old proposal for the city of los angeles to adopt open source and apply the money saved to hiring more police officers, and finds that the proposal appears to have gone off the rails. i wish i could say i was surprised.
but something that comes out in the report filed about current open source usage by the city is there are several departments using mysql, including the city ethics commission, and several others that think they could use it. cool.
we’re* hatching plans for a mysql performance tuning & optimization workshop in los angeles the week of october 24. if that’s the sort of thing you would be interested in, let our tenacious sales people know.
to be clear, this would not be free — these workshops are usually $995/person.
- and by we, i mean not me.
kaj arnö is the latest mysql executive to get bitten by the blogging bug. he’s going to be taking up the mantle of vp/community relations soon. zack urlocker, our vp/marketing, was the first executive to jump on the bandwagon.
i spent my day hammering kittens porting mysql to sco openserver 6 today, a subject of some controversy.
i would not have mentioned it, except that it gave me another excuse to link to that page from everything can be beaten by chancre scolex (jhonen vasquez) and crab scrambly (brad canby). i’d buy a print of that page in a heartbeat.
more jobs at mysql
it occurred to me that i mentioned the product engineer position, but there are a number of other jobs at mysql that are open, including web developer.
if you love fiddling around with various strange unix flavors (and microsoft windows) and slowly trying to obsolete yourself with perl scripts, product engineer for mysql ab might be the job for you.
ninety minutes
here’s how i spent ninety minutes of work today: having been asked to look at a timing related bug, i came to the conclusion that writing a good test case really required i implement an an old feature request for a sleep() function. ninety minutes later, the code is written, approved by brian aker, and pushed to the main 5.0 tree.
and it’s the first function i’ve ever added to mysql. oh yeah, and i ate dinner while i was waiting for brian to review my patch.
i’ve also got the test case written for the other bug. but there’s some question as to what the standards-defined behavior really is — from my reading of the sql:2003 spec, it’s implementation-defined. apparently our standards gurus (now on vacation) left other impressions.
we’ll probably work it out so you can get either behavior depending on what function you call to get the current timestamp.
update: thirty minutes later, paul dubois has documented the new sleep() function. i love it when a plan comes together.
mysql on mactel
it was released without any fanfare, but the most recent release of mysql 5.0, 5.0.10, is available for mac os x on x86. i believe the next version of 4.1 will also be built on that platform.
democratizing development
democratizing innovation by eric von hippel is a fairly dry, academic business book, which made it tougher than i had expected to get through. there are some interesting observations and insights in the book, but they are perhaps too few and far between. you can read the book online.
over on planet mysql, the related topic of distributed version control has gotten some attention, with some shout-outs to free tools for doing distributed development. (i’ll add one for mercurial.)
ian bicking tries to argue in favor of centralized scm systems, but i think he’s neglecting the cost imposed on the center of the project by such centralized systems that the distributed systems do a really good job of distributing — you can impose something even better than his proposed “we don’t accept patches, we only accept pointers to branches in our repository” — “we don’t accept patches, we only pull changes from publically-available repositories.”
i can’t imagine the security nightmare of providing global check-in access to everyone, and the complexity of tools that would be required to manage the layers of dead-end branches.
here is monty and david’s letter to the open source community — in japanese. you can also find the link to the english version there, but it looks cooler in japanese.
mysql mints
 there were a bunch of these in the marketing stockpile in our seattle office. i grabbed a bunch, but now i’m almost out.
there were a bunch of these in the marketing stockpile in our seattle office. i grabbed a bunch, but now i’m almost out.
i also grabbed a nifty travel mug. now i just need to start drinking coffee. and travel.
 i spent the last few days in seattle, meeting with the developers of the various mysql connectors.
i spent the last few days in seattle, meeting with the developers of the various mysql connectors.
while in seattle, i stayed at the moore hotel, in downtown seattle. the building is just two months newer than where i live. i guess not all of the floors have been refurbished, but the room i had was great (and pretty cheap).
this is the first time i spent any time in seattle, and still didn’t take any time to do any sightseeing at all. but seattle seems like a cool city, and i probably should do that some day.
one observation: i took the bus to the office from my hotel, and it was a much, much whiter crowd than i’ve ever seen on any bus in los angeles. i was impressed by seattle’s bus system.
play the home game
you can see all of the active bugs currently assigned to me in the mysql server. it’s currently thick with patches pending but not yet approved.
so far this year, i’ve fixed 122 verified bugs. that’s on pace for one bug per working day. whew.
now if only the rate at which bugs were introduced was less than one per working day, we’d be set.
pthread_rwlock_wrlock bug on amd64 with hoary hedgehog
my otherwise-painless upgrade to ubuntu’s hoary hedgehog release was marred by a bug in pthread_rwlock_wrlock() on amd64 that was fixed in the upstream glibc more than a year ago. ugh.
i wonder what the policy of ubuntu is with regard to fixing things like this. i really hope i don’t have to created a patched glibc myself.
on the bright side, the upgrade fixed the xserver configuration, so now it starts up and shows the pretty login screen. i logged in and it looked and sounded pretty.
testing non-blocking reads on mac os x
here’s a small program to test non-blocking reads that i wrote to try and diagnose a problem with mysql on mac os x. the surprising thing to me is that i have occasionally seen reads that returned with EAGAIN take about 15000 µsec. on my x86_64 linux development box, nothing ever cracks the 20 µsec reporting threshold in the code.
infoworld caught on that other open-source projects are facing a decision about bitkeeper besides the linux kernel. while the article mentions we’re looking at subversion as an alternative for mysql server development, i don’t imagine that will be our long-term solution. distributed version control is just too nice. but our gui team has been using subversion for their projects for quite a while, and we are using it in many other places.
mercurial is another new distributed version control system that looks promising. i may give it a try with my personal projects.
certifiable
i took the mysql pro certification a couple of weeks ago (in prague), and found out today that i passed. i guess that is a good sign for someone who spends his work day hacking on the guts of the server. or that i still eat multiple choice tests for lunch.
like some other open source projects, mysql is celebrating it’s tenth anniversary (birthday?) this year. you can buy a coffee mug to commemorate the event.
according to monty, version 1.0 of mysql was released (“internally”) on may 23, 1995. happy birthday, mysql! the anniversary of the first public release is still a few months away.
short tags and other php coding things
i like php’s short tags. i feel sad for people who feel they need to use the ‘<?php’ construct all the time. or worse, ‘<?php echo’ where a ‘<?=’ will do.
one part of my always-evolving personal php coding style is how i embed sql statements into my code. i used to generally do it like:
$query = "SELECT id,name,url,rss,md5sum,method,updated AS up,"
. " UNIX_TIMESTAMP(lastchecked) AS lastchecked,"
. " UNIX_TIMESTAMP(updated) AS updated"
. " FROM blogs "
. " WHERE updated > NOW() - INTERVAL 10 MINUTE AND method = 0"
. " ORDER BY up DESC"
. " LIMIT 10";
but lately i’ve been doing:
$query= "SELECT id,name,url,rss,md5sum,method,updated AS up,
UNIX_TIMESTAMP(lastchecked) AS lastchecked,
UNIX_TIMESTAMP(updated) AS updated
FROM blogs
WHERE updated > NOW() - INTERVAL 10 MINUTE AND method = 0
ORDER BY up DESC
LIMIT 10
";
it makes it easier to cut-and-paste into the mysql client for testing.
here are the slides from my “embedded mysql” talk. they probably aren’t terribly interesting on their own.
"do we really need databases?" -- om malik, moderator of "scaling and high availability" panel.
(that's a paraphrase, but i thought it was a funny question.)
at the conference
i'm on the hook for being the "session buddy" for lots of talks today, which means i should be trying to make sure speakers don't go too long. (which i didn't do a great job of doing this morning, but i'll be better this afternoon!)
the crowd here is pretty impressive. the ballroom for the morning keynotes was basically full, and the expo hall had a bit of a traffic jam going afterwards (where we had cake to celebrate mysql's 10th anniversary).
andrew cowie's session on managing operations was great, with lots of references to works outside of the information technology sphere, like management within the military and nasa.
yazz atlas did a session that gave an overview of some of the monitoring tools that ostg (slashdot, etc) uses to manage their infrastructure.
james duncan davidson will be the photographer at the mysql users conference. great! i don’t know if he was already lined up to do it, but i pushed from the mysql side to make sure he got signed up as our photographer after seeing his first shots from etech. even with the screwy color balance on this first shots, it was clear that he had a much better handle on conference photography than the guy we had at our last conference.
you’ll be able to see the photos from the mysql users conference as they’re posted to flickr.
mike hillyer posted the sessions he plans to attend at the mysql users conference, and that seems like a good idea to me. so here’s mine (excluding the keynotes), with almost no overlap with mike’s list:
- tuesday
- (10:30) guru best practicies: c and server coding or livejournal’s backend: a history of scaling: i always enjoy hearing about the crazy stuff they do at livejournal, but i’m also curious to hear what turns up at the guru session with brian and monty.
- (11:20) managing lamp stacks with open source tools: nagios, mrtg, etc.: these are tools i should know more about.
- (13:30) utilizing the mysql spatial extension to create an interactive atlas of the island of ireland: gis is nifty stuff, and it will be nice to hear how someone is using our support for it.
- (14:20) panel discussion: scaling and high availability challenges: should be an interesting discussion.
- (16:00) looking for tickets to see your favorite sports team, musical artist or museum exhibit? find them at ticketmaster powered by mysql! or query optimization for subqueries and joins: i’m curious to hear about what ticketmaster has done, but also should know more about how query optimization works for subqueries and joins. i’m torn.
- (16:50) mysql cluster features and roadmap: my knowledge of mysql cluster is spotty, so this could help fill in the blank spaces.
- wednesday:
- (10:30) enterprise mysql: views in mysql 5.0: another thing i should know more about. it cracks me up that “enterprise” found its way into the title of this talk.
- (11:20) building and optimizing data warehouse “star schemas” with mysql: another topic that just strikes me as interesting.
- (13:30) tour of the mysql source code: i suspect i’ve already had to pick up quite a bit of what brian and monty will be talking about, but it is always good to hear it again.
- (14:20) panel discussion: challenges in the enterprise: this is really an ‘or’ entry, in case i decide to skip out on the second half of the code tour.
- (16:00) new innodb features: something i should know about.
- (16:50) ways for using and extending fulltext: fulltext is an underappreciated mysql feature with too many rough edges. i’m curious to hear what joe stump has done with it.
- thursday:
- (10:30) embedded mysql: my talk. that reminds me, i should really prepare for it.
- (11:20) overview of the mysql 5.0 query optimizer: more stuff i should know more about.
- (13:30) guru best practices: php: i’m one of the gurus, so i have to be there. before i remembered this, i had wikimedia, mysql, and free software or writing storage engines for mysql in my list.
- (14:20) real world web scalability: i get to watch ask show off.
of course, i’ll probably only end up attending about half of these. best laid plans, and all that.
O_NONBLOCK broken on darwin and irix?
i’ve been dealing with a mysql bug on irix and mac os x that turned up in our test suite once i fixed the kill test to actually do the test properly. after much digging in code and staring at debug traces, i noticed on irix that in the thread that is being killed, it was stuck in a blocking read that the calling code believed would be non-blocking.
by changing our setting of the non-blocking mode to use both O_NDELAY and O_NONBLOCK instead of just O_NONBLOCK, i was able to get the code to work. but i’m not sure why it is necessary.
on the bright side, this may also fix this bug about wait_timeout not working on mac os x.
i may not be doing web development for my day job any more, but i put a little more elbow grease into the mysql bugs database to add two new features that people have asked for at various times: subscribing to updates on bugs, and making private comments. i also cleaned up the database structure a bit. for example, instead of storing email addresses for the assigned developer and reviewer, it actually has a proper link to the user database.
it’s not a particularly pretty code base (although i clean it up as i go), but i’m rather fond of this little bugs system.
cnet’s coverage of the bitkeeper kerfuffle revealed the osdl employee who drove the wedge: andrew tridgell, of samba fame.
bitmover is dropping the free version of bitkeeper, which is a shame. i’m not sure that we have decided what to do. i wish bazaar ng was a little further along. it looks like it is shaping up to be the best-of-breed of the new generation of open-source version control systems.
 i
i got suckered into agreed to pick up some slack at this year’s mysql user conference, and will be giving a talk on “embedded mysql.”
the conference should be a lot of fun this year — from what i’ve heard, the number of signups has been huge, and we’re still four weeks away. one of the tutorials, advanced mysql performance optimization, is already sold out. being back in the bay area is definitely a good thing for this sort of conference.
wait, did someone just say four weeks away? i guess i need to figure out what this embedded mysql stuff is all about.
i’ll also be doing what is called guru best practices: php with andi gutmans.
build times
something i measured a week or two ago is how long it took to build mysql 5.0 on my new development box (on linux). mainly i was measuring to see if it mattered whether i redirected the output to /dev/null, a file, or just let it fly by on the terminal window. it turns out that didn’t make a different at all. doing a full ./BUILD/compile-amd64-debug-max on my machine, with a populated ccache, takes about seven minutes (without ccache, it takes a little over fifteen minutes). just doing the configuration part (the -c flag to the build script) takes a minute and a half.
i have to admit i was a little disappointed by these times, i was hoping for faster. but then i compile on some of our regular build machines, and i am happy. some of those are painfully slow.
e= mc²
obviously my furious pace of work-related blogging tapered off pretty quickly. i’ve still been fighting the good fight against bugs (two swatted today).
something i’ve always been very flexible on is coding style, so i haven’t had much trouble adapting to the coding style for the mysql server, although my brace-placement reflexes need some re-training. one rule it has that i haven’t run across before is how assignment is handled, with the equal sign next to the variable name, like so:
lower_case_table_names= arg;
this makes it easy to use basic search tools (like grep or vim’s / command) to find where assignments to a particular variable happen, without also getting hits at equality tests, which should always have a space between the variable name and ==.
compiling mysql 5.0 from the development tree on ubuntu linux
i started setting up my new development machine today. it’s an amd64, and so far i’ve installed ubuntu linux on it. the installation was totally painless. to be able to compile mysql 5.0 from the bitkeeper source tree, i had to install automake1.8, autoconf, libtool, gcc, g++, ccache (not a requirement, but nice), bison, gawk (mawk doesn’t work), libncurses5-dev, and libssl-dev. and those pulled in various dependencies thanks to the magic of apt-get.
one new bug fixed today, and two old bugs re-fixed. (mostly — still waiting for the build and test for one of them.)
i fought the bugs, and the bugs won
no bugs fixed today. i spent almost the entire day chasing a single bug that has turned out to be like one of those loose threads on a sweater that you shouldn’t pull.
on the bright side, my new machine arrived so i have something to play with tomorrow.
(and i’m so close to ordering a mac mini. i think apple is going to do very well with that machine.)
just another manic monday
today was another of those one-bug days (but i also spent a fair amount of time on web-related tasks). that one bug took a long time to solve because it only showed up on qnx, and i had to do battle with our qnx build machine to get it to build at all for me. i eventually tracked it down to a shell issue where libtool would have one of its variables get corrupted with the default shell (ksh). i’m not sure why our regular builds on that platform don’t encounter the same problem.
but dealing with the bug did remind that i should probably ask for an okay to purchase vmware for my new box (arrives tomorrow!), so i can run multiple operating systems on it without having to reboot all the time. that would let me run platforms like qnx and solaris locally, which would probably be handy.
i spent a lot of time today waiting for compiles and tests to run. my new machine is scheduled to be delivered on tuesday, and i hope it will be (a lot) faster than the machine i’m currently using. i’m also not using ccache yet, which should be a big help. i don’t know why i haven’t just installed ccache on my current development machine. i guess i’m dumb.
six bugs today, which gives a total of nineteen for the week. i don’t mean to over-sell that number, though — lots of the bugs have been very minor, basically cosmetic, problems. i think my largest patch has been about ten lines of new code. but the best patch is the one that replaced about sixteen lines of code with two.
as wide as a river and harder to cross
apple made just the announcement i was hoping they would, and have dropped the price of cinema displays. still pondering selling my imac and getting a 20" cinema display to hook up to my laptop and new desktop machine.
one of the reasons i want a cinema display is for the extra horizontal working space. extra vertical space doesn’t do much for me, but being able to position a couple of terminal windows side by side, or better yet, a couple of terminal windows next to a web browser or my mail client (which is really just mutt in a big terminal window), is great. i’m still playing around with different setups for having different windows for coding and testing. maybe i’ll have more to say about that when i find a setup i like.
my coworker stewart wrote about how he organizes his working bitkeeper trees, and did some analysis of how much diskspace each clone takes up. what he hasn’t stumbled upon is how you can change bitkeeper to default to always checking out read-only copies of the files instead of read-write copies (which is how the mysql trees are configured by default). in BitKeeper/etc/config, you can add a line like [jimw:]checkout:get to default to read-only files. if you look in the mysql-4.1 tree, you’ll see that serg (the lucky guy who has gotten to approve most of my bug fixes), arjen, and nick (a former coworker) have configured their default to read-only. another advantage to using get by default (instead of edit) is that bk citool is considerably faster, since it doesn’t have to check all those writable files to see if they’ve been modified.
i only fixed one bug today, but i pushed a whole bunch of my approved bug fixes into the tree.
i also spent a little time polishing the mysql bugs database a little. now that i have to use it every day, i have a more active interest in making it better. (and for all of its flaws, i still like it quite a bit. the interface is nice and lean in comparison to so many other bug databases that i’ve seen or worked with.)
ducks in a row
while i wait for my super-cool new development machine, i’ve been using one of our spare servers in uppsala, sweden. surprisingly, network lag hasn’t been an issue at all.
one of the routines i’ve been working out is how to use bitkeeper effectively to maintain trees for each of the bugs i’m working on. bitkeeper’s “branching” is quite a bit different from cvs. a branch is just a clone of another repository. so i have a pristine version of each mysql version in directories like mysql-4.1-clean, and a little shell function (which is just a wrapper around bk clone -l) that allows me to quickly create a new tree named something like mysql-4.1-7451. then i do what i need to do in that tree and create a changeset for the fix. when it is approved, i pull the changes from that tree (and other trees with approved bug fixes) into the -clean tree, push that to the main repository, and get rid of the bug-fixing trees.
this means that each bug fix is independent, and i can push any of them up the tree at any time. (bitkeeper doesn’t let you selectively push changesets from one repository to another.) i have seven bug-fix trees in my working directory right now with patches waiting to get approved.
only three bugs fixed today. i fixed another bug, but when running the fix by the man (because he happened to be around, and the fix just seemed way too easy to be true), he pointed out that it was already fixed in the 5.0 tree. in the same way. oops!
still on pace
five bugs fixed, one marked can’t-repeat.
and too much time wasted spent doing builds with a too new version of automake. ah, the bleeding edge. it cuts so good. (if you are compiling mysql 5.0 from the bk tree, you want automake 1.8, and not 1.9. or so i’ve been led to believe.)
and i ordered my new development machine (and an msdn subscription so i can do windows-y things.) more on those when they arrive.
the year of reunions
i’m supposed to have drinks with one group of old coworkers next week, a different group of old coworkers is having a get-together a few days after that, my ten-year college reunion is in april, and there’s other reunions in the works. so it is the year of reunions.
one fun thing is that when people ask me what i do, i can now tell them i’m a maintenance engineer. i don’t know about you, but the first thing i think when i hear that title is janitor. which is also sort of accurate, if you put “code” in front of it.
i fixed four bugs today. that puts me on a pace for fixing approximately 750 bugs this year. but i guess it may be a little early in the year to make projections like that.
new job
after the first of the year, i’ll be starting my new job. but as seems to be the trend these days, it’s not a new job with a new company, just a new job with the same company.
i’m getting out of doing web development, at least for my day job. that’s why mysql ab is hiring a webmaster (which isn’t exactly the job i have now, but it basically the person who will take on the biggest chunk of what i was doing).
what i’m going to be doing is joining the development team, with my initial focus being maintenance programming for the server. i’m going back to my roots, and getting my hands dirty with “real” programming again. and i don’t think there’s any better way to learn the ins-and-outs of a system than chasing down bugs. just fixing the bug in how CREATE TABLE ... SELECT statements were logged for replication gave me a good reason to get up-to-speed on several aspects of how things work under the hood.
this article by rands about the type of employee who has gotten locked into a role goes part of the way in explaining why i’m moving on from my current position. even if trying to become irreplaceable by being the only one who knows how to do something is not your goal, it is easy for that to happen by default if you’re in the same position for too long. so i hope that shaking things up will be good for the company as a whole, and not just for own own mental health.
one thing i’ll likely do early in the new year is get a new machine for doing development. i’m thinking of a athlon64 shuttle system, which i can get pretty loaded within my annual work computer budget. i may also upgrade my desktop (which is a personal machine) so that i can use the monitor with the development box when necessary (although it would run headless most of the time, and i doubt i’ll spring for a kvm or anything fancy like that). instead of actually getting a new desktop machine, one possibility is just selling the 17" imac and getting an apple cinema display and using that with my laptop (and the development machine).
(the fact that said development machine would likely be powerful enough to run world of warcraft well is entirely coincidental.)
enemies of carlotta is a mailing list manager in the style of ezmlm, but written in python by lars wirzenius. one problem with it is that it is written as a pretty monolithic application, as opposed to ezmlm’s series of commands that are run for a few different addresses. but there’s some interesting design decisions made. it doesn’t implement digests yet.
one of my biggest annoyances with ezmlm these days is that the digest generation is not character-encoding aware. so for a list like the mysql japanese list, the digests, particularly the plain-text one, look like garbage. this is more frustrating because i spent a fair amount of time making sure the web-based archive got the encoding issues right.
the mysql lists are set up so that both mime-encoded and plain-text digests are generated, using a dummy list and some judicious symlinks. when we took over the maxdb lists from sap, the existing lists only had a plain-text format, and the subscribers clamored for that when we only had the mime-encoded versions available.
three out of four ain’t bad
mysql 4.1.8 is out and it includes a fix for the bug that had been plaguing blo.gs. it also contains a fix i made for another bug.
i now have code in linux, mysql, and php. if only my patch to apache had been accepted, i’d have code in the whole LAMP stack. (the CookieDomain configuration setting was finally added about two years later, but not using my patch.)
more later.
another planet
planet mysql collects the blogs of various mysql employees and community members. (well, the only community members included right now are ex-employees.)
mysql users conference call for papers extended
the conference website doesn’t reflect the new date yet, but the call for papers for the mysql users conference is being extended until november 15. so you have a second chance if you missed the initial call for papers, and are just hearing about it now. the speaker notification date isn’t changing. we just came to our senses and realized we didn’t need three whole weeks to make decisions on which sessions and tutorials to accept.
with the way things are going, we may have so many great talks that i don’t need to do one.
more on the uc2005 call for papers
i’m the chair for the lamp track, and would gladly accept bribes for submitted proposals. the best bribe is the submission of a good tutorial or session proposal. here’s the summary of the lamp track:
LAMP
This track is for anyone who is already using or considering making the open source LAMP (Linux, Apache, MySQL, PHP/Perl/Python) stack a core component of their software infrastructure. How is the LAMP stack is being used to power massive websites while maintaining a cost-effective TCO?
Topics:
- New LAMP Releases and Features
- Application Architectures
- Best Practices
- Case Studies
- LAMP related components (FreeBSD, NetWare, Windows)
there’s a new site opposing software patents in the european union called, appropriately enough, no software patents! the very clever might notice that the domain is registered in my name (along with the .org and .net variants), which is just a side effect of how the project got initiated within mysql (whose position on patents is online, incidentally). my involvement basically ended at registering the domain names, and they will be getting transferred to someone else soon.
eventum
i have been terribly remiss in not mentioning eventum before. it’s the issue-tracking tool that the mysql support team uses, and it is also used for task-tracking by a growing number of groups within the company. we liked it so much, we hired the author, bought out the software, and got it released under the gpl.
mysql users conference 2005 call for papers now open
submit your proposal now and beat the rush. (proposals are due on november 1, the conference is in april 2005 in santa clara.)
in defense of connect by
something on the near-term todo list in the mysql manual is oracle-like
. every once in a while, someone drops a comment there to say that there’s no way that connect by prior ...connect by should be implemented, because the sql standard specifies another syntax for recursive queries, known as with.
as it turns out, ibm’s db2 implements the with syntax, and here’s a nice article on the difference between the two syntaxes.
i can’t see how anyone can look at that article and clamor for the with syntax instead of connect by. i look at the statement using connect by and the results it gives, and can think of several ways i could apply it in applications i’ve built or want to build. i look at the with syntax and get dizzy. the syntax of with just looks incredibly un-natural, even for sql syntax, in a way that connect by does not.
there are undoubtedly things you can do using the with syntax that you couldn’t with connect by, but nobody has been able to point them out to me. and as far as i can tell from the article on ibm’s site, getting the type of results i’m interested in requires a stored procedure and query that is at least four times as verbose as oracle’s syntax.
(disclaimer: i work for mysql ab, but am not part of the development team, have no special insights into when either syntax will get implemented. i suspect that both will eventually be implemented: connect by as an aid to people transitioning away from oracle and because it is something a lot of people ask for, and with as part of our commitment to supporting the sql standards.)