Entries tagged 'php'
Just make it better

This access hatch on a sidewalk on Main St. in downtown Los Angeles used to have chipped concrete around the edges and the doors had a lot of flex to them when you walked over them. A few weeks ago, it was finally fixed up and now it looks clean, the doors don’t have any flex to them, and my near-daily experience of walking on that stretch of sidewalk feels a little bit better and safer.
Today, the website for the PHP Documentation Team was finally moved to a new host. Everything (or nearly so) related to the installation is on the appropriate repositories, it’s being served up over TLS, some of the code has been cleaned up, and the contribution guide has gotten more focused attention than it has had in several years.
None of this is perfect. None of it is done. But making things incrementally better is the kind of good trouble that I want to continue.
Another side of the fence
I keep running into things about the Zig community that intrigue me. The latest was this post by Loris Cro about “Critical Social Infrastructure for Zig Communities,” where these paragraphs really grabbed me:
We definitely also need bolder moves, but for now let's try to take it one step at a time, starting from structuring our communities around the idea that other interesting Zig communities exist out there, and that we should try harder to at least stay informed of what we all are collectively working on.
Conversely, we should also strive to make it easier for others to keep track of what we are doing. The time for bolder moves will come, but this a strong prerequisite before can we get to those.
Maybe it is because it is a new and small community compared to PHP’s, but the Zig community seems pretty great. Mitchell Hashimoto’s investment in the community is a good sign.
A lot of what Loris wrote about also brought to mind the IndieWeb principles and my own interest in promoting the ideal of doing open source development in the open using open tools. I chafe every time a community is centered on Discord or Slack, or finding that the real discussions and decision-making is happening in inaccessible places. One person’s tight-knit community can be another’s exclusive club.
What we have now
I ran across this RFC “analysis” by Zeev Suraski that was a response to a proposal about PHP adopting a Code of Conduct. Particularly the section headlined “The RFC process is [all that] what we have.”
In it, he says:
A person that joined internals@ only after the RFC process was enacted in 2011 may be excused to believe that the RFC process is all we have, and that it governs every possible aspect of the PHP language. However, that isn't true - and there's ample evidence for that available.
First, there are fundamental principals which date all the way back to the late 1990's, that are apparent to anybody who reads the archives. One of these core tenets was covered above - open unrestricted discussion.
Another, which is just as real, is decision by consensus for critical decisions.
As a principal author of the Voting RFC and as the person who came up with the 2/3 bar - I can say with absolute confidence that it was meant to regulate feature proposals - and not transforming policy changes - which this proposal certainly falls under. You don't only have to take my word for it - there - 'clues' are available all over the various RFC documents, beginning with the Voting RFC itself:
[ ... ]
It's true that since the Voting RFC process was enacted, it was used for limited-scope / tactical policy decisions. However - neither of these imply that it suddenly became as our sole form of governance that can be applied to everything - especially as it attempts to make the giant leap to cover topics like project participation policies, mailing list censorship and full-fledged banning of members. It's also worth pointing out that even in the handful of cases where it was used for minor policy changes - all of these policy changes effectively cleared the bar of decision by consensus, and not just barely clearing a 2/3 bar - which would have implied an extremely controversial decision.
That was five years ago, and it looks like the PHP project has only veered further away from Zeev’s ideal of a consensus-based approach for anything but feature proposals.
Into the blue again after the money’s gone
A reason that I finally implemented better thread navigation for the PHP mailing list archives is because it was a bit of unfinished business — I had implemented it for the MySQL mailing lists (RIP), but never brought it back over to the PHP mailing lists. There, it accessed the MySQL database used by the Colobus server directly, but this time I exposed what I needed through NNTP.
An advantage to doing it this way is that anyone can still clone the site and run it against the NNTP server during development without needing any access to the database server. There may be future features that require coming up with ways of exposing more via NNTP, but I suspect a lot of ideas will not.
Another reason to implement thread navigation was that a hobby of mine is poking at the history of the PHP project, and I wanted to make it easier to dive into old threads like this thread from 2013 when Anthony Ferrara, a prominent PHP internals developer, left the list. (The tweet mentioned in the post is gone now, but you can find it and more context from this post on his blog.)
Reading this very long thread about the 2016 RFC to adopt a Code of Conduct (which never came to a vote) was another of those bits of history that I knew was out there but hadn’t been able to read quite so easily.
Which just leads me to tap the sign and point out that there is a de facto Code of Conduct and a group administering it.
I think implementing a search engine for the mailing list archives may be an upcoming project because it is still kind of a hassle to dig threads up. I’m thinking of using Manticore Search. Probably by building it into Colobus and exposing it via another NNTP extension.
Writing documentation in anger
As I continue to slog through my job search, I also continue to contribute in various ways to the PHP project. Taking some inspiration from the notion of “good trouble” so wonderfully modeled by John Lewis, I have been pushing against some of the boundaries to move and expand the project.
In a recent email to the Internals mailing list from Larry Garfield, he said:
And that's before we even run into the long-standing Internals aversion to even recognizing the existence of 3rd party tools for fear of "endorsing" anything. (With the inexplicable exception of Docuwiki.)
I can guess about a lot of the history there, but I think it is time to recognize that the state of the PHP ecosystem in 2024 has come a long way since the more rough-and-tumble days when related projects like Composer were experimental.
So I took the small step of submitting a couple of pull requests to add a chapter about Composer and an example of using it’s autoloader to the documentation.
The PHP documentation should be more inclusive, and I think the best way to make that happen is for me and others to just starting making the contributions. We need to shake off the notion that this is somehow unusual, not choose to say nothing about third-party tools for fear of “favoring” one over the other, and help support the whole PHP ecosystem though its primary documentation.
I would love to add a chapter on static analysis tools. And another one about linting and refactoring tools. Maybe a chapter on frameworks.
None of these have to be long or exhaustive. They only need to introduce the main concepts and give the reader a better sense of what is possible and the grounding to do more research on their own.
A big benefit of putting this sort of information in the documentation is that there are teams of people working on translating the documentation to other languages.
And yes, contributing to the PHP documentation can be kind of tedious because the tooling is pretty baroque. I am happy to help hammer any text that someone writes into the right shape to make it into the documentation, just send me what you have. If you want to do more of the heavy lifting, join the PHP documentation team email list and let’s make more good trouble together.
Retain that dear perfection

An adjustment to my résumé that I made a while ago was to split out the software engineering work I did for our store into a position at Imperial Dog, Inc. which is the name of the corporation that did business as Raw Materials Art Supplies and served as the production company behind some of Celia’s short films.
I used the title of “Staff Software Engineer” as a sort of anchor to the level that I see myself at, but in hindsight that may have been too aggressive when applying to lower-titled roles like “Senior Software Engineer.” So I’ve updated it to “Consulting Software Engineer” which feels sort of vague and non-leveled and hopefully not similarly off-putting.
I am progressing along the interview path for a few positions now, so I have some hope that this drought will end soon and I can escape this particular purgatory.
I have slowed down on applying to jobs as I hold out hope for the current prospects, and I have been getting more involved with the PHP project again in some of the same ways that I was involved 20+ years ago.
I tackled a couple of projects in the documentation, including filling in some of the missing history of the project, removing some ancient documentation for XForms (a technology that never really got traction), and adding background and supporting material about the hash functions. A couple of these were picked up from outstanding issues in the repository, or inspired by conversations on the internals mailing list about possible upcoming deprecations.
I am also trying to dive in on the infrastructure and governance sides, which is slower going. I have mostly documented who the members of the PHP organization on GitHub are. I have access again to the machine where the mailing lists run, so I have been working on getting its configuration properly handled within the big ball of code that the team uses to manage the project infrastructure, and trying to help clean that stuff up and make sure more of the setup is known and documented. The team supporting all of this infrastructure had dwindled over the years but things have been kind of chugging along.
One way to sum up what I am trying to do by getting involved in the PHP community again is to leverage my privilege (from past participation and the usual privilege I carry) to clean up some of the on-ramps for new people to get involved. It moves more slowly than I would like at times, but I am glad to have this time now to apply pressure to the problems that I see. Seeing how the Python community has organized themselves is an inspiration.
The rules can matter

I had written a variation of this in a couple of spots now and wanted to put it here, this weird place where I keep writing things:
Organizations with vague rules get captured by people who just fill in the gaps with rules they make up on their own to their own advantage, and then they will continuously find reasons that the “official” rules can’t be fixed because the proposed change is somehow imperfect so they force you to accept the rules they have made up.
The first time I ran into this sort of problem was probably in college being involved in student government, but I haven’t been able to come up with the specifics of what happened that makes me think that it was.
A later instance where I came across it that I remember more vividly was when I was involved with the Downtown Los Angeles Neighborhood Council and how one of the executive board members would squash efforts by citing “standing rules” that nobody could ever substantiate.
More recently, I came across it in looking at discussions of why certain people are or are not allowed to vote on PHP RFCs where the lead developers of one or more popular PHP packages have been shut out because of what I would argue is a misreading of the “Who can vote” section of the Voting Process RFC.
But I still haven’t found what I’m looking for
I’m still looking for a job.
It is a new month, so I thought it was a good time to raise this flag again, despite it being a bad day to try and be honest and earnest on the internet.
I wish I was the sort of organized that allowed me to run down statistics of how many jobs I have applied to and how many interviews I have gone through other than to say it has been a lot and very few.
Last month I decided to start (re)developing my Python skills because that seems to be much more in demand than the PHP skills I can more obviously lay claim to. I made some contributions to an open source project, ArchiveBox: improving the importing tools, writing tests, and updating it to the latest LTS version of Django from the very old version it was stuck on. I also started putting together a Python library/tool to create a single-file version of an HTML file by pulling in required external resources and in-lining them; my way of learning more about the Python culture and ecosystem.
That and attending SCALE 21x really did help me realize how much I want to be back in the open source development space. I am certainly not dogmatic about it, but I believe to my bones that operating in a community is the best way to develop software.
I think my focus this month has to be on preparing for the “technical interview” exercises that are such a big of the tech hiring process these days, as much as I hate it. I think what makes me a valuable senior engineer is not that I can whip up code on demand for data structures and algorithms, but that I know how to put systems together, have a broader business experience that means I have a deeper of understanding of what matters, and can communicate well. But these tests seem to be an accepted and expected component of the interview process now, so it only makes sense to polish those skills.
(Every day this drags on, I regret my detour into opening a small business more. That debt is going to be a drag on the rest of my life, compounded by the huge weird hole it puts in my résumé.)
Time to modernize PHP’s syntax highlighting?
This blog post about “A syntax highlighter that doesn't suck” was timely because recently I had been kicking at the code for the syntax highlighter that I use on this blog. It’s a very old JavaScript package called SHJS based on GNU Source-highlight.
I created a Git repository where I imported all of the released versions of SHJS and then tried to update the included language files to the ones from the latest GNU Source-highlight release (which was four years ago), but ran into some trouble. There are some new features to the syntax files that the old Perl code in the SHJS package can’t handle. And as you might imagine, the pile of code involved is really, really old.
That new PHP package seems like a great idea and all, but I really like the idea of leveraging work that other people have done to create syntax highlighting for other languages rather than inventing another one.
On Mastodon, Ben Ramsey brought up a start he had made at trying to port Pygments, a Python syntax highlighter, to PHP.
I ran across Chroma, which is a Go package that is built on top of the Pygments language definitions. They’ve converted the Pygments language definitions into an XML format. Those don’t completely handle 100% of the languages, but it covers most of them.
At the end of the day, both GNU Source-highlight and Pygments and variants are built on what are likely to remain imprecise parsers because they are mostly regex-based and just not the same lexing and parsing code actually being used to handle these languages.
PHP has long had it’s own built-in syntax highlighting functions (highlight_string() and highlight_file()) but it looks like the generation code hasn’t been updated in a meaningful way in about 25 years. It just has five colors that can be configured that it uses for <span style="color: #...;"> tags. There are many tokens that it simply outputs using the same color where it could make more distinctions. If it were to instead (or also) use CSS classes to mark every token with the exact type, you could do much finer-grained syntax highlighting.
Looks like an area ready for some experimentation.
How I use Docker and Deployer together
I thought I’d write about this because I’m using Deployer in a way that doesn’t really seem to be supported.
After the work I’ve been doing with Python lately, I can see how I have been using Docker with PHP is sort of comparable to how venv is used there.
On my production host, my docker-compose setup all lives in a directory called tmky. There are four containers: caddy, talapoin (PHP-FPM), db (the database server), and search (the search engine, currently Meilisearch).
There is no installation of PHP aside from that talapoin container. There is no MySQL client software on the server outside of the db container.
I guess the usual way of deploying in this situation would be to rebuild the PHP-FPM container, but what I do is just treat that container as a runtime environment and the PHP code that it runs is mounted from a directory on the server outside the container.
It’s in ${HOME}/tmky/deploy/talapoin (which I’ll call ${DEPLOY_PATH} from now on). ${DEPLOY_PATH}/current is a symlink to something like ${DEPLOY_PATH}/release/5.
The important bits from the docker-compose.yml look like:
services:
talapoin:
image: jimwins/talapoin
volumes:
- ./deploy/talapoin:${DEPLOY_PATH}This means that within the container, the files still live within a path that looks like ${HOME}/tmky/deploy/talapoin. (It’s running under a different UID/GID so it can’t even write into any directories there.) The caddy container has the same volume setup, so the relevant Caddyfile config looks like:
trainedmonkey.com {
log
# compress stuff
encode zstd gzip
# our root is a couple of levels down
root * {$DEPLOY_PATH}/current/site
# pass everything else to php
php_fastcgi talapoin:9000 {
resolve_root_symlink
}
file_server
}(I like how compact this is, Caddy has a very it-just-works spirit to it that I dig.)
So when a request hits Caddy, it sees a URL like /2024/03/09, figures out there is no static file for it and throws it over to the talapoin container to handle, giving it a SCRIPT_FILENAME of ${DEPLOY_PATH} and a REQUEST_URI of /2024/03/09.
When I do a new deployment, ${DEPLOY_PATH}/current will get relinked to the new release directory, the resolve_root_symlink from the Caddyfile will pick up the change, and new requests will seamlessly roll right over to the new deployment. (Requests already being processed will complete unmolested, which I guess is kind of my rationale for avoiding deployment via updated Docker container.)
Here is what my deploy.php file looks like:
<?php
namespace Deployer;
require 'recipe/composer.php';
require 'contrib/phinx.php';
// Project name
set('application', 'talapoin');
// Project repository
set('repository', 'https://github.com/jimwins/talapoin.git');
// Host(s)
import('hosts.yml');
// Copy previous vendor directory
set('copy_dirs', [ 'vendor' ]);
before('deploy:vendors', 'deploy:copy_dirs');
// Tasks
after('deploy:cleanup', 'phinx:migrate');
// If deploy fails automatically unlock.
after('deploy:failed', 'deploy:unlock');Pretty normal for a PHP application, the only real additions here are using Phinx for the data migrations and using deploy:copy_dirs to copy the vendors directory from the previous release so we are less likely to have to download stuff.
That hosts.yml is where it gets tricky, because when we are running PHP tools like composer and phinx, we have to run them inside the talapoin container.
hosts:
hanuman:
bin/php: docker-compose -f "${HOME}/tmky/docker-compose.yml" exec --user="${UID}" -T --workdir="${PWD}" talapoin
bin/composer: docker-compose -f "${HOME}/tmky/docker-compose.yml" exec --user="${UID}" -T --workdir="${PWD}" talapoin composer
bin/phinx: docker-compose -f "${HOME}/tmky/docker-compose.yml" exec --user="${UID}" -T --workdir="${PWD}" talapoin ./vendor/bin/phinx
deploy_path: ${HOME}/tmky/deploy/{{application}}
phinx:
configuration: ./phinx.ymlNow when it’s not being pushed to an OCI host that likes to fall flat on its face, I can just run dep deploy and out goes the code.
I’m also actually running Deployer in a Docker container on my development machine, too, thanks to my fork of docker-deployer. Here’s my dep script:
#!/bin/sh
exec \
docker run --rm -it \
--volume $(pwd):/project \
--volume ${SSH_AUTH_SOCK}:/ssh_agent \
--user $(id -u):$(id -g) \
--volume /etc/passwd:/etc/passwd:ro \
--volume /etc/group:/etc/group:ro \
--volume ${HOME}:${HOME} \
-e SSH_AUTH_SOCK=/ssh_agent \
jimwins/docker-deployer "$@"Anyway, I’m sure there are different and maybe better ways I could be doing this. I wanted to write this down because I had to fight with some of these tools a lot to figure out how to make them work how I envisioned, and just going through the process of writing this has led me to refine it a little more. It’s one of those classic cases of putting in a lot of hours to end up with a relatively few lines of code.
I’m also just deploying to a single host, deployment to a real cluster of machines would require more thought and tinkering.
Oracle Cloud Agent considered harmful?
Playing around with my OCI instances some more, I looked more closely at what was going on when I was able to trigger the load to go out of control, which seemed to be anything that did a fair amount of disk I/O. What quickly stuck out thanks to htop is that there were a lot of Oracle Cloud Agent processes that were blocking on I/O.
So in the time-honored tradition of troubleshooting by shooting suspected trouble, I removed Oracle Cloud Agent.
After doing that, I can now do the things that seemed to bring these instances to their knees without them falling over, so I may have found the culprit.
I also enabled PHP’s OPcache and some rough-and-dirty testing with good ol’ ab says I took the homepage from 6r/s to about 20r/s just by doing that. I am sure there’s more tuning that I could be doing. (Requesting a static file gets about 200 r/s.)
By the way, the documentation for how to remove Oracle Cloud Agent on Ubuntu systems is out of date. It is now a Snap package, so it has to be removed with sudo snap remove oracle-cloud-agent. And then I also removed snapd because I’m not using it and I’m petty like that.
Coming to you from OCI
After some fights with Deployer and Docker, this should be coming to you from a server in Oracle Cloud Infrastructure. There are still no Ampere instances available, so it is what they call a VM.Standard.E2.1.Micro. It seems be underpowered relative to the Linode Nanode that it was running on before, or maybe I just have set things up poorly.
But having gone through this, I have the setup for the “production” version of my blog streamlined so it should be easy to pop up somewhere else as I continue to tinker.
Docker, Tailscale, and Caddy, oh my
I do my web development on a server under my desk, and the way I had it set up is with a wildcard entry set up for *.muck.rawm.us so requests would hit nginx on that server which was configured to handle various incarnations of whatever I was working on. The IP address was originally just a private-network one, and eventually I migrated that to a Tailscale tailnet address. Still published to public DNS, but not a big deal since those weren’t routable.
A reason I liked this is because I find it easier to deal with hostnames like talapoin.muck.rawm.us and scat.muck.rawm.us rather than running things on different ports and trying to keep those straight.
One annoyance was that I had to maintain an active SSL certificate for the wildcard. Not a big deal, and I had that nearly automated, but a bigger hassle was that whenever I wanted to set up another service it required mucking about in the nginx configuration.
Something I have wanted to play around with for a while was using Tailscale with Docker to make each container (or docker-compose setup, really) it’s own host on my tailnet.
So I finally buckled down, watched this video deep dive into using Tailscale with Docker, and got it all working.
I even took on the additional complication of throwing Caddy into the mix. That ended up being really straightforward once I finally wrapped my head around how to set up the file paths so Caddy could serve up the static files and pass the PHP off to the php-fpm container. Almost too easy, which is probably why it took me so long.
Now I can just start this up, it’s accessible at talapoin.{tailnet}.ts.net, and I can keep on tinkering.
While it works the way I have it set up for development, it will need tweaking for “production” use since I won’t need Tailscale.
Enabling GD’s JPEG support in Docker for PHP 8.3
I am generating a ThumbHash for each photo in my new photo library using this PHP library, and it needs to use either the GD Graphics Library extension or ImageMagick to decode the image data to feed it into the hash algorithm.
The PHP library recommends the ImageMagick extension (Imagick) because GD still doesn’t support 8-bit alpha values, but I ran into the bug that prevents Imagick from building that is fixed by this patch that hasn't been pulled into a released version yet. Then I realized that none (or close to none) of the images I’d be dealing with use any sort of transparency, so GD would be fine. And it was already enabled in my Dockerfile, so I should have been good to go.
But it turns out that although I thought I had included GD, I hadn’t actually properly enabled JPEG support in GD, so the ThumbHash library’s helper function to extract the image data it needed just failed on a call to ImageSX() after ImageCreateFromString had failed. (Here is a pull request to SRWieZ/thumbhash to throw an exception on that failure, which would have saved me a few steps of debugging.)
Looking at the code for the GD extension, that should not have been a silent failure, so some digging may be required to figure out what happened with that. I may have just missed that particular error message in the logs.
Enabling JPEG support is fairly simple, although a lot of the instructions I found online were a little out of date. The important thing was that I needed to add this to my Dockerfile between installing the development packages and building the PHP extensions: docker-php-ext-configure gd --with-freetype --with-jpeg.
So now I can successfully generate a ThumbHash for all of my photos, except for another bug I haven’t tracked down yet where it sometimes produces a hash that is longer than expected. The ThumbHash for this photo is 2/cFDYJdhgl3l2eEVMZ3RoOkD1na which can be turned directly into this image:

Where to put routing code
I won’t make another Two Hard Things joke, but an annoying thing in programming is organizing code. Something that bothered me over the years as I was developing Scat POS is that adding a feature that exposed new URL endpoints required making changes in what felt like scattered locations.
In the way that Slim Framework applications seem to be typically laid out, you have your route configuration in one place and then the controllers (or equivalent) live off with your other classes. Slim Skeleton puts the routes in app/routes.php and your controller will live somewhere down in src. Scat POS started without using a framework, and then with Slim Framework 3, so the layout isn’t quite the same but it’s pretty close. The routes are mostly in one of two applications, app/pos.php or app/web.php, and then the controllers are in lib.
So as an example, when I added a way to send a text message to a specific customer, I had to add a couple of routes in app/pos.php as well as the actual handlers in lib.
(This was an improvement over my pre-framework days where setting up new routes could involve monkeying with Apache mod_redirect configuration.)
Finally for one of the controllers, I decided to move the route configuration into a static method on the controller class and just called that from within a group. Here is commit adding a report that way, which didn’t have to touch app/pos.php.
Just at quick glance, it looks like Laravel projects are set up more like the typical Slim Framework project with routes off in one place that call out to controllers. Symfony can use PHP attributes for configuring routes in the controller classes, which seems more like where I would want to go with this thinking.
I am not sure what initially inspired me to start using Slim Framework but if it seems like I am doing things the hard way sometimes, that is sort of intentional. On a project like this where I was the only developer, it was a chance to explore ideas and learn new concepts in pretty small chunks without having to buy in to a large framework. If I were to start the project fresh now, I might just use Symfony and find other new things to learn (like HTMX). If I had needed to hand off development of Scat POS to someone else, I would have needed to spend some time making things more consistent so there weren’t multiple places to look for routes, for example.
And as a side note, going back to that commit adding SMS sending to customers, you can see a bit of the interface I had to for popping up dialogs. It used Bootstrap modal components because it pre-dates browser support for <dialog>. The web side of Scat POS actually evolved that to use browser-native dialogs (as a progressive enhancement) because I had rebuilt it all more recently and that side no longer used Bootstrap.
thought i missed one: oscommerce
i ran across a reference to oscommerce in the slides of a tutorial i presented at o’really oscon in 2002(!) where i ran through of a survey of major php applications, and i thought that meant i had missed one in my round-up of open-source php point-of-sale applications.
but it’s an ecommerce platform, not a point-of-sale system and it doesn’t look like it has a module or add-on to provide a point-of-sale interface.
speaking of that, there are some point-of-sale add-ons for woocommerce, which is itself the ecommerce add-on to wordpress. it looks like the only open-source/free ones are built specifically for use with square or paypal terminals.
titi, a simple database toolkit
at some point in my life i got tired of writing all my SQL queries by hand, and was casting about for a database abstraction that simplified things. but i didn’t care for anything that required that i specify my actual SQL tables in code or another format. i wanted something that would just work on top of whatever tables i already had.
i don’t know what i considered at the time, but where i landed was using Idiorm and Paris, which bills itself as a “minimalist database toolkit for PHP5” which gives you a sense of its age. it was long ago put into maintenance-only mode by its developers, and eventually i ran across something that i wanted to fix or otherwise do that i knew would never be accepted upstream.
so i took the code that was in two distinct repositories, merged it together, tossed it in a new namespace, and renamed it Titi. i haven’t really done much with it beyond that, but i know there is code that i should be pulling back in from scat. an advantage to being a solo developer is you can kind of punch through abstraction layers to get things done, but that also leaves cleanup work to be tackled eventually.
should anybody else use this? maybe not. but it has been useful for me in my projects, and it’s also been a good playground to learn more about new php language features and tools.
(like most of my open source projects, this is named for a type of monkey, the titi monkey.)
scat is scatter-brained
while i folded all of the website/ecommerce parts of scat into the same repository as the point-of-sale system itself, it doesn’t really work out of the box and it is because of the odd way in which we run it for our store. the website used to be a separate application that was called ordure, so there’s a little legacy of that in some class names. i still think of the point-of-sale side as “scat” and the website side as “ordure”.
the point-of-sale system itself runs on a server here at the store (a dell poweredge t30), but our website runs on a virtual server hosted by linode. they run semi-independently, and they’re on a shared tailscale network.
ordure calls back to scat for user and gift card information, to send SMS messages, and to get shipment tracking information. so if the store is off-line, it mostly works and customers can still place orders. (but things will go wrong if they try to log in or use gift cards.)
there are scheduled jobs on the scat side that:
- push a file of the current inventory and pricing (every minute)
- pull new user signups (every minute)
- check for new completed orders and pull them over (every minute)
- push the product catalog and web content if a flag was set (checked every minute)
- push updated google/facebook/pinterest data feeds (daily)
- send out abandoned cart emails (daily)
so ordure has a copy of scat’s catalog data that only gets updated on demand but does get a slightly-delayed update of pricing and inventory levels. the catalog data gets transferred using ssh and mysqldump. (basically: it get dumped, copied over, loaded into a staging database, and a generated 'rename table' query swaps the tables with the current database, and the old tables get dropped so the staging area is clear for next time.)
not all of this is reflected within the scat code repository, and this post is just sort of my thinking through out loud where it has ended up. part of the reason for this setup is that the store used to have a janky DSL connection so i was minimizing any dependencies on both sides being available for the other to work.
as a side note, all of the images used in the catalog are stored in a backblaze b2 bucket and we use gumlet to do image optimizing, resizing, etc. when we add images to our catalog, it can be done by pulling from an external URL and the scat side actually calls out to the ordure side to do that work because when we were on that crappy DSL connection, pulling and pushing large images through that pipe was painful.
php pieces of what?
back in july 2010 i wrote about how i was frustrated with our point of sale system (Checkout, a Mac application which changed hands once or twice and is no longer being developed) and had taken a quick survey around to see what open source solutions there were.
the one that i mentioned there (PHP Point of Sale) is still around, but is no longer open source. here is a very early fork of it that still survives. i know at least one art supply store out there is using it (the closed-source version, not that early fork), but i haven’t really looked at it since 2010.
there are a few more php point of sale systems now.
the biggest is called Open Source Point of Sale and appears to be undergoing an upgrade from CodeIgniter 3 to CodeIgniter 4 right now. i spent a few minutes poking around the demo online, and i don’t think i would be happy using it. it is under an MIT license.
another big one is NexoPOS, which is GPL-licensed. i have not played around with the demo, but the supporting website looks pretty slick.
most of the others look like they are just experimental projects or not being actively used or developed.
something i think about a lot is whether i should be trying to take Scat POS beyond just using it ourselves. part of me feels like i am a seasoned enough developer to know that the work that would be required to give it the level of polish and durability to survive usage outside of our own doors could be substantial.
sidekiq for php?
it is a little strange still developing in php and having done it for so long, because you look at how other systems are built today and it isn’t always clear how that translates to php.
mastodon (the server software) is built primarily with ruby-on-rails, and uses a system called sidekiq to handle job processing. when you post to your mastodon server, it queues up a bunch of jobs that push it out to your subscribers, creates thumbnails of web pages, and all sorts of other stuff that may take a while so it makes no sense to make the web request hang around for it.
for scat pos, there are a few queue-like tasks that just get processed by special handlers that i use cron jobs to trigger. for example, when a transaction is completed it reports the tax information to our tax compliance service, but if that fails (because of connectivity issues or whatever) there’s a cron job that runs every night to re-try.
as best i can tell, the state of the art for php applications that want to have some sort of job queue system like sidekiq is Gearman and GearmanManager and it is wild to me that projects i remember starting up in 2008 are still just chugging along like that.
stable and well-understood technologies
AddyOsmani.com - Stick to boring architecture for as long as possible
Prioritize delivering value by initially leaning on stable and well-understood technologies.
i appreciate this sentiment. it is a little funny to me that what i can claim the most expertise in would probably be considered some of the most stable and well-understood technologies out there right now, but i have been working with them since they were neither. perhaps i have crossed from where as long as possible becomes too long, at least as far as employability is concerned.
scat pos proof of life (screencasts)
i recorded a couple of quick screencasts to show cloning it from github and starting it up with docker-compose and going through the initial database setup and processing a sale with sample data.
like the website says, the system is a work in progress and not suitable for use by anyone, but we have been using it for more than ten years.
i am not sure if it is something that anyone else would want to use, but i figure one way to find that out is to at least start pushing it towards where that is even be feasible.
another php akismet api implementation
in poking around with adding support for comments here, i looked at integrating with the akismet anti-spam service, and the existing php libraries for using it didn’t work how i wanted or brought in dependencies that i wanted to avoid. so i made a simple akismet-api package that just uses guzzlehttp under the hood.
i haven’t made a test suite or added real documentation yet, so you should consider it pre-production, but it seems to work okay.
cleantalk is another anti-spam service that we use for registrations and comments on our store website and their php library is kinda non-idiomatic and strange, too. a reimplementation of that might be in the cards.
migrated to slim framework 4
a couple of weeks ago i finally took some time to upgrade the code for this blog to the latest major version of the slim framework. it is still a strange mash-up of framework and hand-coded sql queries and old php code but this should make it easier to for me to tinker with going forward. the main thing i need to do is add a way to post images again.
siamang: a web-based command-line client for mysql
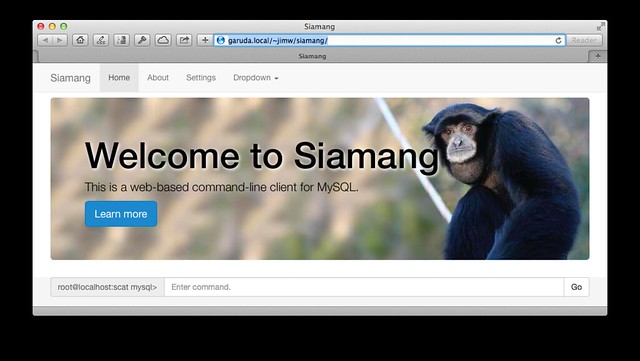
because i have many more important things to be doing, i procrastinated by whipping up a little web-based command-line client for mysql. what does that mean? you load the webpage, start typing in sql commands, and it presents the results to you. it is just a weekend hack at this point, and has a lot of rough edges. it does have some cool features, though, like a persistent command-line history using Web Storage.
probably the biggest limitation is because it not maintaining a persistent connection on the backend, you can’t use variables, temporary tables or transactions.
it was really born because i was getting frustrated running queries using the command-line client and having the ASCII table look all wonky because it was too big for my terminal screen. html makes that pretty much a non-issue. it is also tablet-friendly.
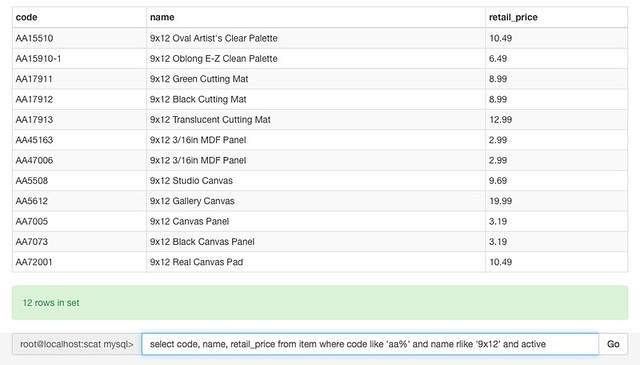
it was also an excuse to play with a few things i was interested in, like knockout. the whole thing is under 400 lines of code/html right now, but by leveraging bootstrap and knockout, it actually looks pretty polished and functional.
the name comes from a type of gibbon, which seemed to be unused in the software world.
you can find the source on github.
what is 10% of php worth?
i am listed as one of the ten members of the php group. most of the php source code says it is copyright “the php group” (except for the zend engine stuff). the much-debated contributor license agreement for PDO2 involves the php group.
could i assign whatever rights (and responsibilities) my membership in the php group represents to someone else? how much should i try to get for it? i mean, if mysql was worth $1 billion....
i am still disappointed that a way of evolving the membership of the php group was never established.
independence day for code
as i’ve been threatening to do for quite some time, i’ve finally made the source code for bugs.mysql.com available. it is not the prettiest code, and there’s still all sorts of hard-coded company-specific stuff in there. but it is free code, so stop complaining.
it is available as a bazaar repository at http://bugs.mysql.com/bzr/. i have not yet set up any sort of fancy web view, or mirrored it to launchpad.
i plan to do the same for the lists.mysql.com code some day. one limiting factor now is that machine only has python 2.3 on it, and bazaar needs python 2.4.
angry programming
mysql doesn’t have quite the number of fancy internal applications that you might suspect, and i got frustrated when the company started to roll out a system of monthly time-off reports based on emailing around an excel spreadsheet. (to add icing to that cake, they kept sending out the excel sheet with password protection!)
last friday, i spent an afternoon cooking up this little proof-of-concept application that tracked the same information as the spreadsheet, but in tasty web format, with some ajax goodness (courtesy of prototype).
as it turns out, there was an official company tool for doing this that was in the works, but they hadn’t bothered to let anyone know it was imminent. i’m told it is sox-compliant and configurable six ways to sunday. i haven’t seen it yet.
so my meager efforts did not go to waste, i just spent another half hour to make this a standalone demo (rather than tying into our internal personnel database). perhaps someone else can find some use for it, or take some inspiration from it.
here’s the simple workflow for the application:
- employee clicks on days they took off in a month.
- employee clicks button to get month approved, which sends email to boss.
- boss reads email and follows link to view the report online.
- boss clicks the button to approve the report, which sends mail to the employee and the finance department.
- the finance department does whatever it does with the data. the employee can no longer change it.
obviously that’s not quite all you would want for a fully-functional application, but it is most of the way there. i think it’s already better than the system that involved emailing an excel spreadsheet around.
where should i be lurking?
trying to find places where people talk about using python, ruby, and php with mysql has been a bit of a challenge.
the problem on the php side is that php forum on forums.mysql.com is so filled with pre-beginner-level questions that it’s barely worth it for me to spend my time digging through it.
for python, the python forum on forums.mysql.com is nearly a ghost town. the forums for the mysql-python project seem slightly active, but the sourceforge forum interface is just bad. (not that any web-based forum isn’t starting from a bad place.) the db-sig mail archives also have some interesting discussions.
for ruby, the ruby forum on forums.mysql.com is even quieter than the python one, and i haven’t found anywhere else.
another thing i’ll take a look at is apr_dbd_mysql, which is not part of the main apr-util repository because of licensing issues (ugh).
where else should i be looking?
more technobabble
working on the mysql bugs system filled the transition from me working on falcon to joining the connectors team, where i’ll be focusing on the connectivity for scripting languages.
my initial focus will be on python, ruby, and php. i haven’t figured out exactly what it is that i’ll be doing, but a likely candidate for my first big task will be building out the test suites for these so that they can eventually become part of our build verification process.
…and they never check out
right on schedule, i’m done with the pressing changes we wanted to make to the mysql bugs system. the most visible things (to non-mysql employees) are probably just the cleanup of the layout of the bug pages themselves, and the new public tagging interface. (with the requisite ajax-y goodness.)
under the hood, i’ve taken a machete to some of the more egregious bits of code. that’s not to say there isn’t a lot more that could be cleaned up, but it’s a start. now that i’ve cleaned up the bug reporting and editing forms, they’re ripe for merging.
based on the priorities set by the developement management team, i did less of the cleanup of the main bugs schema than i had originally planned, but things are in a state now that it should be easier to tackle those in the future.
my plan is to release this code publicly, but one of the things i need to do first is transition it out of bitkeeper and into another revision control system. probably bzr, but i really wish it supported per-file commit messages.
slides from my talks at the mysql users conference 2006
short and simple: “embedding mysql” and “practical i18n with php and mysql.”
the i18n talk seemed to go over pretty well, and i only ran a few minutes short. the embedding talk is yet to come, and will run really, really short.
i would recommend the scale out panel instead.
one month to go
 the mysql users conference 2006 is only a month away. i’m just going to be dropping in for one day to give two talks — “embedding mysql” and “practical i18n with php and mysql.”
the mysql users conference 2006 is only a month away. i’m just going to be dropping in for one day to give two talks — “embedding mysql” and “practical i18n with php and mysql.”
there is also a great lineup of other speakers, tutorials, and keynotes. i’m going to miss the keynote by mark shuttleworth, but i am looking forward to the keynote by the founder of rightnow.
stefan esser has dug up and fixed more php xml-rpc vulnerabilities, and best of all, has worked with the package maintainers to purge them of their use of eval().
stefan can be a bit of a blowhard, but it’s excellent work like this that makes that easier to swallow.
more jobs at mysql
it occurred to me that i mentioned the product engineer position, but there are a number of other jobs at mysql that are open, including web developer.
the race is on
stefan esser dissects one tip in a bad article about php, but is merciful in leaving the others alone. one thing you’ll note if you line up this second article with the first article is that not only are the tips not very good, the author can’t count to ten.
and on the useful-php-news front, andrei’s unicode work* has landed in the php development tree, and rasmus sparked a long discussion of other php6 features. the perennially lost cause of trying to rename functions and change their argument order resurfaces, of course, but it doesn’t look like anyone is taking it all that seriously.
the race is now on between perl6 and php6.
- other people have been involved, i’m sure. i just don’t know who they are.
there was a hole in the pear xml-rpc package, and as a result many php-based applications had a security hole as a result, such as the many php blogging apps.
the thing is, this came about because the xml-rpc library builds up some code and calls eval(). whoever wrote code to parse xml-rpc by building code and calling eval() should have their computer taken away. and then possibly be beaten with it.
the pear code is actually a fork of edd dumbill’s php xml-rpc code, and this is not the first security hole that has been discovered in that code as a result of this positively shameful architecture. i will not be at all surprised if it is not the last.
and for those keeping score at home, i pointed out how dumb this was almost four years ago.
a few resources
here’s a few resources that someone may find helpful:
- php’s htmlspecialchars() function, useful for encoding user input that may contain characters like <
- php’s addslashes() function, useful for escaping user input for putting into an sql query (even better is to use a parameter-based query api)
- a list of the top ten php security vulnerabilities
and don’t forget that in php, variables like $_SERVER['REQUEST_URI'] and $_SERVER['HTTP_REFERER'] are user input.
happy birthday, php
just ten short years ago, php appeared on the scene.
the first time i wrote any php code was about eight or nine years ago. the most recent was about eight or nine minutes ago.
thanks to everyone who has made that all possible. especially, of course, rasmus, who we blame it all on. (well, most of us do.)
short tags and other php coding things
i like php’s short tags. i feel sad for people who feel they need to use the ‘<?php’ construct all the time. or worse, ‘<?php echo’ where a ‘<?=’ will do.
one part of my always-evolving personal php coding style is how i embed sql statements into my code. i used to generally do it like:
$query = "SELECT id,name,url,rss,md5sum,method,updated AS up,"
. " UNIX_TIMESTAMP(lastchecked) AS lastchecked,"
. " UNIX_TIMESTAMP(updated) AS updated"
. " FROM blogs "
. " WHERE updated > NOW() - INTERVAL 10 MINUTE AND method = 0"
. " ORDER BY up DESC"
. " LIMIT 10";
but lately i’ve been doing:
$query= "SELECT id,name,url,rss,md5sum,method,updated AS up,
UNIX_TIMESTAMP(lastchecked) AS lastchecked,
UNIX_TIMESTAMP(updated) AS updated
FROM blogs
WHERE updated > NOW() - INTERVAL 10 MINUTE AND method = 0
ORDER BY up DESC
LIMIT 10
";
it makes it easier to cut-and-paste into the mysql client for testing.
crystal ball
i look forward to the future articles about how ibm is going to control php.
URI::Fetch is a new perl module from ben trott (of movable type renown) that does compression, ETag, and last-modified handling when retrieving web resources. the lazyweb delivers again.
speaking of that, i found i had to do one additional thing to my php code that fetches pages because of a non-existent workaround for server bugs in the version of curl i’m using. so when blo.gs fetches a page to verify a ping and gets a particular compression-related error, it goes back out and requests the page again without compression.
repeating myself
for the blo.gs cloud service, i had written a little server in php that took input from connections on a unix domain socket and repeated it out to a number of external tcp connections. but it would keep getting stuck when someone wasn’t reading data fast enough, and i couldn’t figure out how to get the php code to handle that.
so i rewrote it in c. it’s only 274 lines of code, and it seems to work just fine. it was actually a pretty straightforward port from php to c, although i had to spend some quality time refreshing my memory on how all the various socket functions work.
there’s a visible bump in the graph of my outgoing bandwidth from after this was fixed.
three out of four ain’t bad
mysql 4.1.8 is out and it includes a fix for the bug that had been plaguing blo.gs. it also contains a fix i made for another bug.
i now have code in linux, mysql, and php. if only my patch to apache had been accepted, i’d have code in the whole LAMP stack. (the CookieDomain configuration setting was finally added about two years later, but not using my patch.)