Entries tagged 'web'
Now coming to you from IONOS
I was checking out the “zero-emission web hosting” providers listed at Get Green Hosting and noticed that IONOS (formerly known as 1&1) has a $2/month virtual private server (VPS) plan that should be totally adequate to run this website. So I spent a couple of hours setting one up, and now this is it.
The only hassle in getting the server set up is I had to reboot to make sure the IPv6 address I added was correctly being used by the VPS and my container setup, and I had to set up a swap file so it wouldn’t go into a tailspin when I tried to do too much.
It looks like the server is located at their datacenter in New Jersey, but I’m not actually sure.
I have been with Linode for just over 17 years, but I haven’t felt the same loyalty since they were acquired by Akamai, which has always seemed like a pretty soulless corporation.
This probably isn’t really a move that pays off in any meaningful way (getting that hosting bill down to $24/year instead of $60/year), but it was an interesting exercise. Looks like Akamai isn’t on 100% renewable energy yet, except for their Seattle datacenter, so this is an improvement on that front.
Curly’s Drive Thru
What follows is a paper I wrote for a course at Harvey Mudd College in March of 1995. It was a seminar in “Advanced Operating Systems” but really it was a hands-on lab class where we had small teams who each set up a Sun server and did various projects. It was taught by Mike Erlinger, now retired. If I remember correctly, the assignment for this project was for each of us to set up some sort of service or software on the system and write up what we did. My team’s server was named “Curly.”
Here is a scanned PDF of the paper, but I’ve also turned it back into HTML (actually Markdown) here. Mostly via OCR, so there may be typos. Unfortunately, I don’t have any of the configuration files or other code that is being talked about in the paper.
Curly's Drive-Thru
Serving Dynamic and Static Documents on the Web
This is a tour of Curly’s Drive-Thru - a sample demonstration of another stop on the so-called information superhighway, made particularly agonizing to read with the frequent use of fast-food metaphors.
A Brief History of the Web
Using the term in its broadest sense, the Web refers to all the information available 'out there' on the net, whether it is being served by the old stand-bys such as gopher and ftp, or the dominant method of what is usually called the Web, HTTP (or hypertext transfer protocol for those who like the long version).
HTTP and HTML developed almost concurrently with gopher (and it is almost unfortunate that gopher gained the attention it did before HTTP and HTML caught on). Originally developed at CERN, a research laboratory in Europe, the Web did not really start to take off until a program called Mosaic was developed at the National Center for Supercomputing Applications at the University of Illinois in Urbana-Champaign. Mosaic was a graphical browser for the Web, and slowly the power of a graphical interface to the vast resources of the Internet was realized.
Since then, the Web has exploded, with HTTP traffic alone taking up progressively more of the bandwidth of the net, and basically drowning out everything, except possibly Usenet news. The commercial possibilities of the Web are just beginning to be realized, with smaller companies and technical companies leading the way, but with everyone else close on their heels (witness the presence of something as mundane as Zima on the Web).
The Business Plan (HTTP and HTML)
As alluded to above, the primary type of document being pushed around the net as a Web document is called an HTML document. A derivative of SGML, HTML stands for Hypertext Markup Language, and ti is a way of adding information to text about what sort of information each part is (a header, a list, or just part of a paragraph of text), some information about how to display it, hypertext links, and other information.
The primary method of transport for this information is called HTTP, or Hypertext Transfer Protocol. HTTP is a stateless protocol that is similar in many ways to the basic gopher protocol, but more flexible. Combined with the MIME standards, almost any sort of data can be transmitted using HTTP.
Paving the Driveway (Installing a Server)
On Curly, I've elected ot install the NCSA (National Center for Supercomputing Applications, located at the University of Illinois in Urbana-Champaign) Web server, called NCSA httpd. Three other highly-regarded servers include the CERN httpd, BSDI's plexus, and John Hopfield's WN. All four of these are excellent servers, but I selected to install the NCSA httpd because I have found it to be very cleanly coded (thus easy to change) and powerful enough for my needs without all sorts of extra features that I don't need (such as CERN httpd's support for acting as a proxy server, or WN's extensive indexing support).
NCSA httpd can be obtained from ftp.ncsa.uiuc.edu, and documentation is located on the Web from http://hoohoo.ncsa.uiuc.edu/docs/Overview.html. The most recent version as of this writing is 1.3R, which fixes the major security hole found in version 1.3, but version 1.4. is reportedly in the beta-testing stages and should be out "soon."
Because most of NCSA httpd's configuration is done through configuration files, and not at compilation time, compiling the server is very painless. One thing that must be decided before it is compiled, however, is where it is going to be installed. I decided to install Curly's Drive-Thru in /usr/local/www — that's located on the partition with the most free space. This location is referred to as $HOME in the rest of this document.
Wiring the Intercom (httpd.conf)
Most of the configuration for the server itself is done through the file $HOME/conf/httpd.conf. Things that are configured in this file include where various log files go, which port the server should serve documents from, which user the server should run as, and how the server is running (from inetd or standalone).
As I already mentioned, our Web service is based in /usr/local/www, so this is what our ServerRoot is set to in httpd.conf. Three main log files are generated by httpd: the transfer log ($HOME/logs/access), which logs each request sent to the server; the error log ($HOME/logs/errors), where the server logs any errors that it encounters; and the pid file, where the server records its process ID (which is useful for killing or restarting the server).
Our server runs standalone, as opposed to being started by inetd, because in a high-traffic environment, this is more efficient. If httpd were started by inetd instead of running standalone, it would have to parse its configuration files each time someone connected to the server, which causes an avoidable, thus undesirable, strain on the machine's CPU resources. Running the server standalone does inflict some small penalty in the form of memory being used by the server, but this is not a big deal because of the small memory footprint of NCSA's server.
Finally, although the server runs as root because it needs to connect to a priviliged port (80), it is smart enough to change personalities when it dives in the access files that it is going to serve. I have configured our server to turn itself into the "www" user and join the "www" group, which is the same user that owns all of the documents that are going to be served (convenient coincidence?).
Arranging the Menu (srm.conf)
Another configuration file, srm.conf, controls certain aspects of how the server is going to serve documents. This is where you tell the server where the top of the document tree is (that is, the first file to serve to people when they access the site), where user's personal pages are stored, and various files and names to treat ni special ways.
Here I've set it up so that the top of Curly's Drive-Thru is located in /usr/local/www/curly, and the document to serve when a user specifies only a directory and not a specific filename is index.html. This allows the use of shorter URL's such as http://curly.cs.hmc.edu/ instead of the more complete http://curly.cs.hmc.edu/index.html. I've also specified "www" as the directory in each user's home directory for their personal Web pages to be located. That is, if a user on Curly wants to offer a file on the Web called "mypage.html," they can place it in a www/ directory of their home directory and tell people to access it with a URL of the form http://curly.cs.hmc.edu/~user/mypage.html.
It's also possible to set up aliases for certain frequently-used directories, such as where a collection of icons are contained. Also, a command must be put in this file to tell the server where all of the "CGI" programs are located. These are explained more fully later, but basically they are programs that might generate HTML files on their own or process incoming data from users.
Lastly, most of the srm.conf file is dedicated to configuring how the server presents directories where no index.html file is located. What the NCSA httpd does is to build a menu of files from the directory, which pretty little pictures for files and directories.
Setting the Prices (access.conf)
It is probably desirable for a server administrator to be able to regulate which users may access some files. For example, we might want to limit some items on our server to only on-campus users and not just anyone from the rest of the Internet.
The access.conf file allows the server administrator to set up the default access permissions for directory hierarchies, and tell the server which of those permissions can be overridden by a file called htaccess in subdirectories. Some of the things that can be allowed (or disallowed) include symbolic links, CGI scripts, server-side includes, and server-generated indexes. Usually one would want to be more strict with directories that the administrator might not have direct control over, especially user's directories.
Our server is set up fairly liberally, with symbolic links and indexes allowed any place, and with access allowed to everybody by default.
Installing the Menu and Intercom (HTML and CGI)
As mentioned in the brief history of the Web given above, the primary type of document served over the Web is an HTML file. Such a file is very similar to an ordinary text file, but with special tags included to indicate where paragraphs start and stop, and where various hypertext links should be included. Because it's not really the focus of this document, and there are a plethora of other good sources about writing HTML files, I won't go into any details about such things.
One thing worth mentioning, however, issi the support provided by the NCSA httpd server for so-called "server-side" includes. This extends HTML files slightly by allowing them to contain "include" directives similar to what you might see in C source code. This is useful for doing things like including signatures on the bottom of each file that contain information about the author and when the document was last modified.
One of the most useful things that a Web server such as NCSA's httpd server can do is support the use of CGI programs. CGI stands for "Common Gateway Interface," and specifies how the server talks to auxiliary programs called 'gateways.' These programs can provide a window from the Web to other databases of information, such as HMC's UserInfo system. Typically, CGI programs have information passed to them by users through HTML forms, but they can also be used to do things like transparently serve the user different documents depending on where they are connecting from or what browser they are using.
To allow users the ability to have their own CGI applications hosted by Curly, I've installed a program called 'cgiwrap.' This program acts as a wrapper around user's CGI scripts, and does some very simple security/error checking to at least keep the user partially honest. It will not prevent the user form writing a CGI program that simply sends /etc/passwd, but there is also nothing to stop the user from simply emailing that same file, so there is really not much of an additional security hole exposed here. It does allow the user the chance to shoot himself or herself in the foot by allowing access to some of their own files unwittingly, so its use should be monitored. Fortunately, cgiwrap creates a log of all the files that are accessed through it so user's CGI applications can be more thoroughly checked by hand to make sure they're not doing anything nasty. It's worth mentioning that NCSA httpd could (and maybe should) be modified to do the same sorts of checking, but it does not currently.
As an example of a CGI application, I've created a what I've called, rather simply, Jim's Quote Server. It is a pair of CGI scripts that allow users to add quotes to an online collection of quotes, and access that database of quotes (currently by getting a random selection, but eventually to include searching the database). While not particularly fancy, the application is a good example of using perl to write CGI applications, and how to handle different aspects of the service through a small number of individual scripts (for example, the same script is used to generate the form for submissions and to handle submissions).
Changing the Register Tape (Maintenance)
Once a Web server is up and running, the most time-consuming thing is adding documents and services. But, like many of the other servers on everyone's system, httpd generates a slew of log messages that need to be handled in some fashion. In addition to the typical archiving and scanning-for-important-things that one does with log files, some people also choose to generate statistics about their Web server from their logs and make those statistics available on their server as well. There is an excellent package available called getstats which generates all sorts of tables of information, and probably even graphs, but I have not looked at installing it on Curly yet.
Customer Satisfaction (A Note on Standards)
Because the technology of the Web is evolving so rapidly, it is interesting to watch how the standards have emerged. In the beginning, there were relatively few people involved with HTTP, HTML, and other such issues of the Web, so very little was actually set in stone and most of what could be called standards were simply common practice. Many of the things that have since become standards, such as in-line images, were simply how the first person with the idea implemented them (in many cases the developers of NCSA Mosaic, one of the first major graphical Web browsers). Other standards such as CGI were developed once the need was recognized, and usually were simply developed by discussions between a few developers (in the case of CGI, the authors of NCSA httpd and the plexus server, mainly). Now that people have realized that there is money (and substantial amounts of it) to be made from the Web, there is much more politicking involved in developing standards. While NCSA Mosaic clearly violated existing standards (or at least standard practice) when it added support for inline images, not much of an outcry was raised because the standards weren't cemented and there were fewer people involved. When Netscape Communications (then Mosaic Communications) released the first version of their browser, Netscape, there was a rather large outcry about the features that it supported that were non-standard, such as the CENTER tag and the infamous BLINK. Netscape was blasted on the net for allegedly ignoring the HTML/2.0 and HTML3 standards under development.
This has continued with Netscape Communication's announcement and strong push for its security protocol called SSL. Many people on the net have been resistant to Netscape's proposal because they feel that Netscape is simply bullying the W3C (the World Wide Web Consortium, the organization responsible for the development of the Web) by confronting them with a protocol that is already implemented by the most popular browser, Netscape, which gives them a strategic advantage over their competitors. The discussions surrounding Netscape Communication's behavior in these issues is interesting because of the unique position of the company, and the untiring personal involvement of Marc Andressen, one of the original authors of NCSA Mosaic, and one of the founders of Netscape Communications.
Personally, I have adopted many of what have been dubbed "Netscapisms" in pages I've created because they should be simply ignored by most other browsers, and they are really nice for the vast number of users that use Netscape out there.
Would you like fries with that? (Bibliography)
(Unfortunately, this wasn’t included in my remaining print out of the paper.)
Introducing Frozen Soup
I made a new thing, which I decided to call Frozen Soup. It creates a single-file version of an HTML page by in-lining all of the images using data: URLs, and pulling in any CSS and JavaScript files.
It is loosely inspired by SingleFile which is a browser extension that does a similar thing. There are also tools built on top of that which let you automate it, but then you’re spinning up a headless browser, and it all felt very heavyweight. The venerable wget will also pull down a page and its prerequisites and rewrite the URLs to be relative, but I don’t think it has a comparable single-file output.
This may also exist in other incarnations, this is mostly an excuse for me to practice with Python. As such, it is a very crude first draft right now, but I hope to keep tinkering with it for at least a little while longer.
I have also been contributing some changes and test cases to ArchiveBox, but this is different yet also a little related.
Grinding the ArchiveBox
I have been playing around with setting up ArchiveBox so I could use it to archive pages that I bookmark.
I am a long-time, but infrequent, user of Pinboard and have been trying to get in the habit of bookmarking more things. And although my current paid subscription doesn’t run out until 2027, I’m not paying for the archiving feature. So as I thought about how to integrate my bookmarks into this site, I started looking at how I might add that functionality. Pinboard uses wget, which seems simple enough to mimic, and I also found other tools like SingleFile.
That’s when I ran across mention of ArchiveBox and decided that would be a way to have the archiving feature I want and don’t really need/want to expose to the public. So I spun it up on my in-home server, downloaded my bookmarks from Pinboard, and that’s when the coding began.
ArchiveBox was having trouble parsing the RSS feed from Pinboard, and as I started to dig into the code I found that instead of using an actual RSS parser, it was either parsing it using regexes (the generic_rss parser) or an XML parser (the pinboard_rss parser). Both of those seemed insane to me for a Python application to be doing when feedparser has practically been the gold standard of RSS/Atom parsers for 20 years.
After sleeping on it, I decided to roll up my sleeves, bang on some Python code, and produced a pull request that switches to using feedparser. (The big thing I didn’t tackle is adding test cases because I haven’t yet wrapped my head around how to run those for the project when running it within Docker.)
Later, I realized that the RSS feed I was pulling of my bookmarks would be good for pulling on a schedule to keep archiving new bookmarks, but I actually needed to export my full list of bookmarks in JSON format and use that to get everything in the system from the start.
But that importer is broken, too. And again it’s because instead of just using the json parser in the intended way, there was a hack to work around what appears to have been a poor design decision (ArchiveBox would prepend the filename to the file it read the JSON data from when storing it for later reading) that then got another hack piled on top of it when that decision was changed. The generic_json parser used to just always skip the first line of the file, but when that stopped being necessary, that line-skipping wasn’t just removed, it was replaced with some code that suddenly expected the JSON file to look a certain way.
Now I’ve been reading more Python code and writing a little bit, and starting to get more comfortable some of the idioms. I didn’t make a full pull request for it, but my comment on the issue shows a different strategy of trying to parse the file as-is, and if that fails, skip the first line and try it again. That should handle any JSON files with garbage in the first line, such as what ArchiveBox used to store them as. And maybe there is some system out there that exports bookmarks in a format it calls JSON that actually has garbage on the first line. (I hope not.)
So with that workaround applied locally, my Pinboard bookmarks still don’t load because ArchiveBox uses the timestamp of the bookmark as a unique primary key and I have at least a couple of bookmarks that happen to have the same timestamp. I am glad to see that fixing that is project roadmap, but I feel like every time I dig deeper into trying to use ArchiveBox it has me wondering why I didn’t start from scratch and put together what I wanted from more discrete components.
I still like the idea of using ArchiveBox, and it is a good excuse to work on a Python-based project, but sometimes I find myself wondering if I should pay more attention my sense of code smell and just back away slowly.
(My current idea to work around the timestamp collision problem is to add some fake milliseconds to the timestamp as they are all added. That should avoid collisions from a single import. Or I could just edit my Pinboard export and cheat the times to duck the problem.)
random business idea
provide an online backup service, but part of the startup is sending the user an external hard drive that they use to do a full backup and return to you before they start doing incremental backups over the network. for 40GB of data, it takes 10 days to upload at a fairly typical (but optimistic) 384KB/s.
mailing a hard drive can have much better throughput than pushing data up through adsl connections, but i wonder if the economics work out.
how i helped some spammer
i’ve been reading through old entries on behind the counter, a blog from someone who works weekends at a wal*mart customer service desk. in an old entry, the author links to another blog they started about their experiences dining out.
now that old blog appears to be abandoned — it redirects to another location which just has a captcha form on it, and the page title “confirm that you are a human being... too many artificial requests sorry.”
without giving it much thought, i dutifully typed in the text for the captcha image. and then was presented with another. looking at the source for the page, it looks like i have inadvertently verified that a particular hotmails.com email address is valid on some forum somewhere.
sorry!
must be something in the air
evan henshaw-plath coins the term coupleware — sites built for two, and brings up wesabe, the financial site i also had in mind when i wrote about services built for two.
services for two
one thing i’ve noticed as we prepare for our wedding is how none of the web-based wedding services seem to have two people in mind. here’s a quote from the help of one online wedding site’s guest list manager:
You can allow your fiance and others access to your online guest list by having them log in to The Knot using your email address and password. Please remind them to log out when they are done, so you'll be able to access your account.
apparently having one list that is accessible by two people would be far too much rocket science.
i wrote our own tool for managing the guest list. it has its own little quirks, but at least when there’s something it doesn’t do, i can fix it. i also hooked up the online rsvp handling to the same database, so for those that choose to rsvp online instead of using the reply card, that information will automatically be linked to our invite list.
and speaking of invitations, the first batch finally went in the mail yesterday. we still have at least one more batch to go, but we really needed to get the out-of-state (and country!) invitations out ages ago now.
wearing your price tag on your sleeve
dropsend is a web-based service for sending large files. carson systems, who created and run the service, are in the process of selling it. they’re blogging the process.
it is sometimes hard to not feel like i am wasting my time (again) in a company where i hold a very small equity stake. (technically, not even that. just options on a very small stake.)
but there are more important things: two months, four days.
web sites are expensive?
reporting about david geffen’s apparent bid for the los angeles times, nikki finke says “He’ll ratchet up the Web site (even though he hates how prohibitively expensive it is to do that).”
prohibitively expensive? i guess there is still a lot of stupid money flowing into web properties. i’m in the wrong line of work.
a strange little side-note: mysql’s website gets more traffic than latimes.com, according to alexa.
hope they don’t uninvite me
the los angeles downtown news took first place, best website (25,000 and above) from the california newspaper publishers association. second place was the palo alto weekly.
i assume this is one of those contests where you only win if you pay to enter. i have to believe there are some weeklies out there in california with websites that are actually interesting.
the landscape pictures for wallpapers blog picked one of my pictures to feature as “wallpaper of the day.” personally, i’ve been using “birds on orange” as my desktop background.
500 of my closest friends
for the first time in a very long time, i shoved all the logs from this site through a web stats package, and have come to learn that this site averages about 500 visits per day.
hi.
deadly commet

i guess if someone is going to take the time to take one of my pictures and do something cool with it (original picture) i guess i should link back to it. here’s another version.
too bad about the spelling.
the first draft of history?
 i’ve been poking around in the historical archives (pre-1985) of the los angeles times. here’s an interesting factoid: “los angeles was the first city in the united states to entirely abandon gas for street lighting and replace it by electricity, which was done january 1, 1888.”
i’ve been poking around in the historical archives (pre-1985) of the los angeles times. here’s an interesting factoid: “los angeles was the first city in the united states to entirely abandon gas for street lighting and replace it by electricity, which was done january 1, 1888.”
and here’s a great blurb from the august 10, 1886 “briefs” column: “officer fonck brought in a man, last night, from los angeles street, who was dead drunk, and so filthy that it caused the officer to lose his four-bit dinner.”
one of the reasons i’ve been digging around is that in this obituary for james pulliam, i noticed that the writer claimed there was some renovation of the central library that was completed in 1987. i thought this was obviously wrong, because the two fires in the central library were in 1986, and the renovation of the library was not completed until 1993. looking at the articles where pulliam is quoted in 1979, they are about a renovation project that was never done. charles luckman, another los angeles architect, had proposed a renovation that would have added two new wings to the library, and had elevators in the central rotunda. the city council killed that plan in september 1979, and plans for the renovation that did happen did not start to gel until a few years later.
the person with the times who first responded to my correction appears to be on vacation for a few days, so maybe they’ll correct the obituary after my latest volley. (or not, and in the grand scheme of things, it’s not a very big deal.)
this piece in the new york times looks at how people appear on the news are getting out their side of the story, and one thing it astutely points out is that an advantage that organizations like the discovery institute or people like me have is that our content doesn’t disappear inside a pay-for-access archive after a few weeks. for the foreseeable future, you’ll be able to come back to this entry to see what i’ve said. this article is something i linked to in the los angeles times almost five years ago (here). the link doesn’t even offer to sell me the article, it just wants me to contact their archive department who may or may not be able to figure out what the article actually was. as a counter-example, here’s a new york times article where i’m offered an archive copy of the article. and here’s an even older one that is still freely available.
except all the others that have been tried
in an o’reilly network article, matthew b. doar asks, “bug trackers: do they all really suck?”
my answer would be yes, but i love tinkering with them anyway. we’re still using a hacked up version of the bugs.php.net code at bugs.mysql.com, despite periodic threats to move us over to bugzilla. some things that block the migration are that we’ve added various bits of workflow and bitkeeper integration into our bug tracker that someone will have to re-do for bugzilla, and someone will also have to figure out how to integrate it into the login infrastructure (and user database) for our websites.
meanwhile, i hack new features and fields into the existing bugs system whenever the need is strong enough.
i can’t tell if i’m a kingpin or a pauper
10 over 100 is a new website from james hong (of hot or not infamy) and josh blumenstock, an employee at hot or not, where people are encouraged to pledge 10% of their income over $100,000 to charity. the new york times had an article about what inspired it (via evhead).
i signed up, but i’m not sure that it is entirely meaningful. i already donate 10% of what i make to charity, and i make less than $100,000. i guess that makes me part of the “10 over 0” club.
someone asked me recently what i spend money on (after i said something about me being cheap), and the obvious answer of “give it away” didn’t occur to me. oops.
tools for the community or vice versa
this wired article about myspace is interesting, but what really caught my eye was justin’s comment about it: “interesting, MySpace has evolved into "indie music + SNS", like Flickr is "photos + SNS"; also, each of the SNSes seems to have found a niche.”
i was thinking almost the exact same thing this morning, but in relation to yahoo! groups. where the groups concept is “form a group, here’s tools for them to use,” the new model appears to be “here’s a tool, form some groups around their use.”
funny characters are not ☢
sam ruby pulled a good quote on building in support for internationalization in web applications, which i agree is really important.
it is very annoying that i can’t use my flickr recent comments feed because the atom feed is broken due to bad utf-8 handling.
i’m thinking of doing another talk at the mysql conference next year about handling this sort of thing. there’s really no excuse for it. which makes it a little hard to do a 45-minute talk on — it’s so easy to get right!
worked a coin from the cold concrete
“breaking the web wide open!” is a long article by marc canter about new open standards on the internet. i’m named as a “mover and shaker” in the pinging space, which i think says volumes about the limits of that space.
mostly the truth
jakob nielsen’s list of the top ten design mistakes in weblog usability are generally reasonable advice, but i think it is funny that cory at boing boing decided to call out the one i probably pay the least heed to: #3, nondescript posting titles.
it’s not that my titles are nondescript so much as non-sequitors, or inside jokes so inside that i’m the only one who could possibly understand them. some recent highlights:
- “mostly the truth” came about because i noticed i had several strategic uses of the weasel-word mostly in this entry. and now i’ve applied it to the whole thing.
- “not bursting into tears” is a reference to the fact that there were numerous times during the day where i was literally on the verge of bursting into tears. (mostly because of my back, which appears to be fine now. knock on wood.)
- “don’t get the wrong idea” is the antidote to the content, which is really deliberately crafted to feed various people’s suspicions that shannon and i are involved.
- “let’s all go to the lobby” is a pop culture reference, of course, to the classic movie theatre advertisement.
- “mmm, rabbits,” besides being a part of the quote i was calling attention to, is sort of an implied simpsons reference.
- “solid gold” is what the students in the film say the professor is made of, because he is so pure.
- “i say hello” is about as obscure as i can get — i originally wrote a bit about how my back pain had flared up to the oh-my-god-where’s-the-vicodin level, and this is a line from a song called “vicodin” by the trainables, a band you’ve never heard of (unless you’re marcus, who was in it).
- “tax that fellow behind the tree” is a fragment of a quote from russell long: “tax reform means “don’t tax you, don’t tax me, tax that fellow behind the tree.’”
- “the soul of this man is in his clothes” is a quote from william shakespeare.
- “more on me and friends” is actually a bit of a play on words — say it out loud, and it is “moron me and friends.”
- “she sets the summer sun on fire” is a line from “i want candy” by good charlotte.
- “looking minnesota, feeling california” is a reversal of a line from “outshined” by soundgarden.
- “flat denial” is one of those titles that i look back on and don’t understand. as i said there, it was in reference to what i started writing about, but i don’t remember what that was any more.
and then there are all the entries i don’t even title.
at the end of the day, i’m (mostly) writing for me, so i like to think that gives me license to flaunt jakob’s list.
let’s all go to the lobby
in film pitch speak, heyletsgo.com is friendster meets upcoming.org meets evite. social networking built around activity planning. another web 2.0 beta site.
this may be the site for you, if you’re not like me and “the most important information in my daily life is, simply, what are my friends doing?”
it may also be the site for you if you know you want to go to some event and want to find a friend-of-a-friend to go with.
the site, inasmuch as i’ve poked around, seems very well done. but as you might have guessed, i just don’t see myself being a regular user. it models a sort of social dynamic that i just don’t feel any resonance with.
drop me a line if you want an invite.
when leonard got in touch with me to pick my brain a little bit about the blo.gs acquisition experience, i didn’t have an inkling that he would be joining yahoo! along with the rest of the upcoming.org team.
congrats!
when i look at the hobbled state of blo.gs, i lament, a little bit, my decision to not go to yahoo with the site.
ugh. so much more i could say. but no more angsty bullshit.
the new hybrid map view on the google maps site totally rocks. google deserves every ounce of praise they get for yanking web maps out of the ad-plastered ghetto they had been consigned to before.
this history of suck is a good read — it sounds like it was one of those too-rare confluences of great people and great fun.
high stakes, no prisoners: a winner’s tale of greed and glory in the internet wars by charles h. ferguson is the story of vermeer technologies, the company that created that created frontpage and was acquired by microsoft. it’s a very personal account of the story, and it’s a good read. ferguson is quite a character, and his characterizations of various dotcom celebrities and microsoft insiders are entertaining.
the book was written about six years ago, and some of his predictions have fallen short in the meantime. microsoft hasn’t really claimed a huge percentage of the server market, and the frontpage server extensions certainly haven’t done much to drive iis adoption.
breathing room
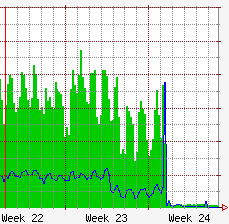 okay, one more little blo.gs tidbit: the effect of being rid of the service on the bandwidth usage of my server.
okay, one more little blo.gs tidbit: the effect of being rid of the service on the bandwidth usage of my server.
the final little spike in outgoing bandwidth (the blue line) is when the final dump of the data was downloaded by the yahoo folks.
the current bandwidth usage is in the 30kbits/sec range. it was generally over 1Mbits/sec before, or at least that’s how it looks from the graphs. (it may have been higher — it appears to get sort of flattened out over time in rrdtool.)
paypal now has a all-in-one payment processing interface, which means you can handle credit cards without even bouncing to the paypal website. i’m amazed this didn’t happen ten years ago — the existing schemes with distinct merchant accounts and gateways has always been dodgy.
you do have to use their express checkout thing (which does bounce to them, and lets users use their paypal account directly) in order to use the direct payment api. it’s $20/month and 2.2-2.9% + 30¢ per credit card transaction or 1.9% + 30¢ per paypal payment.
the best part may be that paypal is a company that seems to know where its towel is. what i’ve often heard from people working with existing providers is that they’re either morons or crooks. (or in the case of verisign, both.)
upcoming.org got some love from its creator, so now you can add private events, among a bunch of other new features. i added a bunch of upcoming events at the los angeles central library.
i had been thinking of building a little event widget for myself, but now i don’t think i’ll need to. at some point i’ll work some magic so my upcoming events show up here, along with my del.icio.us entries.
om malik’s “how yahoo got its mojo back” does a good job of capturing the goodwill that yahoo seems to be generating these days. i bet you can attribute a lot of this to good old-fashioned healthy competition with google.
something i’ve been reflecting on recently is that i’d be a whole lot more excited about this whole social software thing if i weren’t such an unsocial person.
URI::Fetch is a new perl module from ben trott (of movable type renown) that does compression, ETag, and last-modified handling when retrieving web resources. the lazyweb delivers again.
speaking of that, i found i had to do one additional thing to my php code that fetches pages because of a non-existent workaround for server bugs in the version of curl i’m using. so when blo.gs fetches a page to verify a ping and gets a particular compression-related error, it goes back out and requests the page again without compression.
rumor du jour
rumor has it that six apart (makers of movable type blogging software and typepad blogging service) are going to buy live journal (and by live journal, i think they mean danga interactive). it seems like it would be a good fit from what i know of the people involved in both companies and their development platforms. (they’re both perl shops.) and six apart would be getting some of the folks doing the most interesting low-budget, open-source web scalability work that i’ve seen.
rumors that anyone is about to buy blo.gs are completely untrue. unless they aren’t.
2005 prediction?
preshrunk is a new blog dedicated to cool t-shirts you can buy online. i bet we’ll see a whole lot of these blogs focused on little niches like this. (with the existing ones like pvrblog and the gizmodo and weblogs, inc. empires being the pioneers here.) here’s one i thought up over pancakes this morning: a blog dedicated to american animation. anime is well-covered, i think, and i don’t have any interest in anime.
oh, and many of these will be obvious-in-retrospect sorts of ideas. i pointed out the up-swing in online t-shirt retailers back in october.
pingback client
to kill time (see previous entry), i’ve implemented pingback 1.0 client code for when i post. if it works, this entry will ping the spec and ian hickson’s initial announcement of pingback. what are the odds it will work on the first try? answer: not good. it took two tries.
next time i need to kill a few moments, i’ll do the server side.
subscriber counts for los angeles times feeds
i thought i’d do a quick count of how many people are subscribed to each of the scraped the los angeles times news feeds i provide. this is based on unique ip addresses and the bloglines report of subscribers.
- world news: 1745
- national politics: 284
- california politics: 1201
- commentary: 210
- company town: 61
- technology: 428
- food: 102
michael kinsley, editorial page editor of the los angeles times (or some title similar to that i’m too lazy to look up), writes in his column that blogs are better, because he liked the feedback he got in response to something he had published on a couple of popular blogs.
he attributes some of this to space, but it seems the la times has failed to recognize that they have a website. of course, it is an amazingly lame web site, that offers nothing in the way of social interaction, actively discourages you to read articles by collecting pointless demographic information so it can send you email you don’t want, and hasn’t embraced rss or atom. i read the content of three major newspaper web sites now. the washington post , the new york times, and the la times. to read the la times, i had to write code to scrape some of its pages to create rss feeds.
oh, and the three references to websites in kinsley’s column might have been more useful if they were actually links. 2004, and the los angeles times still hasn’t figured out a way to make a link from one of the articles on their website.
stealing an idea (and four lines of code) from shelley powers, i’ve implemented a very basic live comment preview. i need to read up on this xml http request object thing (which this does not use) to try doing other and more clever things. (christian stocker’s livesearch is a good example of clever xml http request object usage.)
that was easy. i bolted on the basic livesearch here. the integration could (and maybe someday will) be improved, but it was quite easy to get going.
i find it somewhat subversive that the google zeitgeist special edition - election 2004 (via jeremy zawodny) uses blue for bush, and red for kerry.
web designer needed
i need someone with some web design skills, and hopefully some illustration/cartoonish-design skills, to do a little work for a personal project of mine. it won’t pay a whole lot, but it should be fun and not a whole lot of work (i think).
i’m gradually turning into one of those people who registers a domain name when any sort of business idea pops into their head. each time, thinking “maybe this will be the one that goes somewhere.”
gawker went offline due to network solutions incompetence. i’d have a touch more sympathy if i could fathom a reason why anybody with two neurons firing would be a willing customer of network solutions. a bit of my respect for the gawker media crew has crawled into the corner to die.
everyone has already linked to the long tail already, but just on the off chance you missed it, here’s another link to it. there’s some really amazing insights in the article, and it is definitely not to be missed.
if you look at the interesting internet advertising plays out there right now, i think the most promising are those that try to bridge the tail of the advertising curve and the tail of the publishing curve. things like blogads that make it easy for a small advertiser to publish on a small publisher’s site. marketbanker is similar. google’s adsense runs the risk of lagging behind because it doesn’t allow a direct connection between an advertiser and publisher. there’s no incentive for me to drive potential advertisers on blo.gs to adsense, which i think is an inherent weakness in their architecture of participation.
i have an idea for a business that would sort of sit in this space. too bad i’ve already got a job.
the snap.com terms & conditions includes a linking policy (which i just violated). the snap.com privacy policy (oops, there i go again) says, in part, “We may share certain information about you with carefully selected business partners, including those who may offer services that complement those provided by us or which we believe may be of interest to you.”
update: cory lays the smack down. with regard to the linking policy, at least. i think i forgot to mention the “we can sell your info to spammers” clause of the privacy policy.
another update: the linking policy got dropped. no change to the privacy policy. (links from boing boing and snap. am i cool yet?)
snap is a new idealab! (oh, i guess they’re “Idealab” now — boring) search company. cnet news.com has the details. i guess i’m too much of a google-lean-and-mean sort of search consumer, since snap really didn’t do anything for me.
but it does remind one of the original snap.com, which was nbc’s bid to get into the portal game. i remember it having a rather nice, plain style, something in the spirit of what myway is doing now.
judging from the posts from jeremy zawodny (who needs a web 2.0 category), it looks like web 2.0 is a heck of a conference. i briefly flirted with the idea of attending, but decided it was too rich for my blood.
(but it’s something i’m very ambivalent about. on the one hand, i can see getting really excited about this whole web 2.0 thing. on the other hand, i am becoming increasingly persuaded that i would be more happy doing something that does not involve sitting in front of a computer for hours at a time. but that may just be october talking.)