Entries tagged 'scat'
Where to put routing code
I won’t make another Two Hard Things joke, but an annoying thing in programming is organizing code. Something that bothered me over the years as I was developing Scat POS is that adding a feature that exposed new URL endpoints required making changes in what felt like scattered locations.
In the way that Slim Framework applications seem to be typically laid out, you have your route configuration in one place and then the controllers (or equivalent) live off with your other classes. Slim Skeleton puts the routes in app/routes.php and your controller will live somewhere down in src. Scat POS started without using a framework, and then with Slim Framework 3, so the layout isn’t quite the same but it’s pretty close. The routes are mostly in one of two applications, app/pos.php or app/web.php, and then the controllers are in lib.
So as an example, when I added a way to send a text message to a specific customer, I had to add a couple of routes in app/pos.php as well as the actual handlers in lib.
(This was an improvement over my pre-framework days where setting up new routes could involve monkeying with Apache mod_redirect configuration.)
Finally for one of the controllers, I decided to move the route configuration into a static method on the controller class and just called that from within a group. Here is commit adding a report that way, which didn’t have to touch app/pos.php.
Just at quick glance, it looks like Laravel projects are set up more like the typical Slim Framework project with routes off in one place that call out to controllers. Symfony can use PHP attributes for configuring routes in the controller classes, which seems more like where I would want to go with this thinking.
I am not sure what initially inspired me to start using Slim Framework but if it seems like I am doing things the hard way sometimes, that is sort of intentional. On a project like this where I was the only developer, it was a chance to explore ideas and learn new concepts in pretty small chunks without having to buy in to a large framework. If I were to start the project fresh now, I might just use Symfony and find other new things to learn (like HTMX). If I had needed to hand off development of Scat POS to someone else, I would have needed to spend some time making things more consistent so there weren’t multiple places to look for routes, for example.
And as a side note, going back to that commit adding SMS sending to customers, you can see a bit of the interface I had to for popping up dialogs. It used Bootstrap modal components because it pre-dates browser support for <dialog>. The web side of Scat POS actually evolved that to use browser-native dialogs (as a progressive enhancement) because I had rebuilt it all more recently and that side no longer used Bootstrap.
scat is scatter-brained
while i folded all of the website/ecommerce parts of scat into the same repository as the point-of-sale system itself, it doesn’t really work out of the box and it is because of the odd way in which we run it for our store. the website used to be a separate application that was called ordure, so there’s a little legacy of that in some class names. i still think of the point-of-sale side as “scat” and the website side as “ordure”.
the point-of-sale system itself runs on a server here at the store (a dell poweredge t30), but our website runs on a virtual server hosted by linode. they run semi-independently, and they’re on a shared tailscale network.
ordure calls back to scat for user and gift card information, to send SMS messages, and to get shipment tracking information. so if the store is off-line, it mostly works and customers can still place orders. (but things will go wrong if they try to log in or use gift cards.)
there are scheduled jobs on the scat side that:
- push a file of the current inventory and pricing (every minute)
- pull new user signups (every minute)
- check for new completed orders and pull them over (every minute)
- push the product catalog and web content if a flag was set (checked every minute)
- push updated google/facebook/pinterest data feeds (daily)
- send out abandoned cart emails (daily)
so ordure has a copy of scat’s catalog data that only gets updated on demand but does get a slightly-delayed update of pricing and inventory levels. the catalog data gets transferred using ssh and mysqldump. (basically: it get dumped, copied over, loaded into a staging database, and a generated 'rename table' query swaps the tables with the current database, and the old tables get dropped so the staging area is clear for next time.)
not all of this is reflected within the scat code repository, and this post is just sort of my thinking through out loud where it has ended up. part of the reason for this setup is that the store used to have a janky DSL connection so i was minimizing any dependencies on both sides being available for the other to work.
as a side note, all of the images used in the catalog are stored in a backblaze b2 bucket and we use gumlet to do image optimizing, resizing, etc. when we add images to our catalog, it can be done by pulling from an external URL and the scat side actually calls out to the ordure side to do that work because when we were on that crappy DSL connection, pulling and pushing large images through that pipe was painful.
php pieces of what?
back in july 2010 i wrote about how i was frustrated with our point of sale system (Checkout, a Mac application which changed hands once or twice and is no longer being developed) and had taken a quick survey around to see what open source solutions there were.
the one that i mentioned there (PHP Point of Sale) is still around, but is no longer open source. here is a very early fork of it that still survives. i know at least one art supply store out there is using it (the closed-source version, not that early fork), but i haven’t really looked at it since 2010.
there are a few more php point of sale systems now.
the biggest is called Open Source Point of Sale and appears to be undergoing an upgrade from CodeIgniter 3 to CodeIgniter 4 right now. i spent a few minutes poking around the demo online, and i don’t think i would be happy using it. it is under an MIT license.
another big one is NexoPOS, which is GPL-licensed. i have not played around with the demo, but the supporting website looks pretty slick.
most of the others look like they are just experimental projects or not being actively used or developed.
something i think about a lot is whether i should be trying to take Scat POS beyond just using it ourselves. part of me feels like i am a seasoned enough developer to know that the work that would be required to give it the level of polish and durability to survive usage outside of our own doors could be substantial.
scat pos proof of life (screencasts)
i recorded a couple of quick screencasts to show cloning it from github and starting it up with docker-compose and going through the initial database setup and processing a sale with sample data.
like the website says, the system is a work in progress and not suitable for use by anyone, but we have been using it for more than ten years.
i am not sure if it is something that anyone else would want to use, but i figure one way to find that out is to at least start pushing it towards where that is even be feasible.
one person's technical debt
My 20 Year Career is Technical Debt or Deprecated
Everything eventually becomes tech debt, or the projects get sunsetted. If you are lucky, your code survives long enough to be technical debt to someone else.
i rather liked this piece on the ever-changing nature of software tools and how entropy catches up with us all, but what a focus on technical debt doesn't quite capture is the underlying value. old code has accumulated a lot of knowledge and value. it's why you don't just rewrite from scratch.
scat pos has been a one-person project for over a decade. at this point, it has literally encoded my experience in how to manage our retail store. you could throw it all away; start from scratch, or just switch to an off-the-shelf solution. but you would be throwing away a lot of accumulated knowledge and value.
another three years
another three years between entries. some stuff has happened. the store is still going, and i am still finding excuses to code and learn new things.
i wrote before about how i was converting scat from a frankenstein monster to a more modern php application built on a framework, which has more or less happened. there’s just a little bit of the monster left in there that i just need to work up the proper motivation to finish rooting out.
i also took what was a separate online store application built on a different php framework and made it a different face of scat. it is still evolving and there’s bits that make it work that aren’t really reflected in the repository, but it’s in production and seems to sort of work, which has been gratifying to get accomplished. the interface for the online store doesn’t use any javascript or css frameworks. between that and running everything behind cloudflare, it’s much faster than it used to be.
the state of things
just over seven years ago, i mentioned that i had decided to switch over to using scat, the point of sale software that i had been knocking together in my spare time. it happened, and we have been using it while i continue to work on it in that copious spare time. the project page says “it is currently a very rough work-in-progress and not suitable for use by anyone.” and that's still true. perhaps even more true. (and absolutely true if you include the online store component.)
it is currently a frankenstein monster as i am (slowly) transforming it from an old-school php application to being built on the slim framework. i am using twig for templating, and using idiorm and paris as a database abstraction thing.
i am using docker containers for some things, but i have very mixed emotions about it. i started doing that because i was doing development on my macbook pro (15-inch early 2008) which is stuck on el capitan, but found it convenient to keep using them once i transitioned to doing development on the same local server where i'm running our production instance.
the way that docker gets stdout and stderr wrong constantly vexes me. (there may be reasonable technical reasons for it.)
i have been reading jamie zawinski’s blog for a very long time. all the way back to when it was on live journal, and also the blog for dna lounge, the nightclub he owns. the most recent post about writing his own user account system to the club website sounded very familiar.
lcdpoled
it turns out that the county of los angeles regulates the use of point-of-sale systems that use barcode scanners. one requirement is that you have a customer-facing display that shows prices as they are scanned.
after investing in a lcd pole display (for about $175), i had to bang together a way for scat to feed data to the display. and thus was born lcdpoled, a very simple daemon that listens for stuff to display.
i need to do some more work to make it as seamless as i would really like, but i think i have done enough to get us through an inspection if and when they stop back in to do that.
cranking along
a few weeks ago, i got it in my head that the ideal time to switch to using scat, the web-based point-of-sale system that i have allegedly been working on for almost 18 months, would be after the new year. this is despite the fact that it was barely even a rough prototype of some ideas. but i’ve been cranking along on it over the last couple of weeks, and it looks like i might just have something that we can use by my arbitrary deadline.
it’s still just barely a rough prototype of ideas, but i there should be enough there on the surface for us to be able to use it, and needing to fill in the gaps because we are actually using it will probably provide plenty of motivation to make it better.
even in the very rough state it is in, it should alleviate some of the pains of our current system. and save us the $30/month we were paying for not-very-helpful support and slow-to-arrive upgrades (trading that for my time to support the new system, of course).
banker’s round for mysql
for some reason, nobody has ever exposed the different rounding methods via mysql’s built-in ROUND() function, so if you want something different, you need to add it via a stored function. the function below is based on the T-SQL version here.
CREATE FUNCTION ROUND_TO_EVEN(val DECIMAL(32,16), places INT)
RETURNS DECIMAL(32,16)
BEGIN
RETURN IF(ABS(val - TRUNCATE(val, places)) * POWER(10, places + 1) = 5
AND NOT CONVERT(TRUNCATE(ABS(val) * POWER(10, places), 0),
UNSIGNED) % 2 = 1,
TRUNCATE(val, places), ROUND(val, places));
END;
use at your own risk. there may be edge conditions where this fails. but this matches up with the python and postgres based system i was crunching data from, except in cases where that system gets it wrong for some reason.
one thing you might notice is that it does not use any string-handling functions like the other “correct” solution floating around out there.
building an order
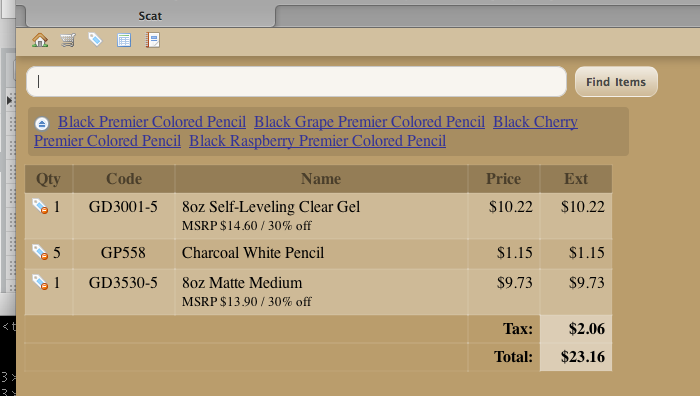
it feels like i’ve been thinking about this point-of-sale thing long enough that when i find time to sit down and write some code, the pieces actually fall together pretty quickly. today i was able to rough together an order-building interface with a few bells and whistles (literally: it has audible cues).
still a long way to go, but this should be a useful little toy to let us take advantage of a spare computer and barcode scanner to more easily price items from incoming shipments and get them out on the shelves.
one of the things that this screenshot shows is what happens when a scan or search matches multiple different items — it adds a (crudely presented) list of the possible matches, and clicking on any one of them adds that item to the order.
three kinds of people
progress on scat continues to be slow, because i have not found a lot of time to work on it. but every week i have to deal with processing our weekly in-take of products with our current point-of-sale system, i kick myself a little more and get motivated to spend a little more time on it.
the big addition today was a table for people, which is pretty straightforward. our current system divides people up into three types (and stores them in the same table as products, thanks to a normalization scheme i have not carried over into scat), and currently i don’t make any such distinction because sometimes customers can become employees and vendors can be customers and we have few enough of all three that keeping them distinct doesn’t seem worth the extra complexity.
scattered progress
scat is the name of the web-based point-of-sale system that i’ve been working on. you might have guessed this if you had been paying attention to the tags on my earlier posts. you can also find the source code for scat on github. there is not much to see, as i am still tinkering and throwing code together to test ideas out.
the progress so far is that i can load all of the item data over from our checkout data, and search those items. one of the most painful things for us right now is receiving orders, so i have cobbled together the start of that functionality to use. we will be able to receive the order using this as we unpack the order, and then go back to checkout and receive the order there all at once through its stock room interface.
(the reason that receiving orders through checkout is so painful for us is that using the stock room interface cripples the performance of checkout. and since we are just using checkout on a single computer, it makes it hard to receive orders while we also want to serve customers.)
this is starting to get fun.
stuff in, stuff out
i know that i said that inventory is next, but i’m not sure that it really is, or at least not in terms of thinking of having an inventory that we add items into and out of. maybe what we really have is a collection of transactions that in their aggregate can be used to describe the inventory.
as i see it, there are three types of transactions:
- vendor transactions: we put together a purchase order, we receive items (which may be more or less than what is on the purchase order and may not happen all at once), and we return items.
- customer transactions: customers order items, we “deliver” items, and customers return items.
- internal transactions: items are damaged, defective or stolen, and we take items for our own use.
so we’ll need a basic table for tracking these transactions (which i will abbreviate to txn because i am lazy):
CREATE TABLE `txn` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`number` int(10) unsigned NOT NULL,
`created` datetime NOT NULL,
`type` enum('internal','vendor','customer') NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `type` (`type`,`number`)
)i am not thrilled with the number field, but we need some sort of user-visible number for printing on invoices, receipts, etc. consider this a placeholder for a better idea.
and for each transaction, we will have lines of items involved:
CREATE TABLE `txn_line` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`txn` int(10) unsigned NOT NULL,
`line` int(10) unsigned NOT NULL,
`item` int(10) unsigned DEFAULT NULL,
`ordered` int(10) unsigned NOT NULL,
`allocated` int(10) unsigned NOT NULL,
PRIMARY KEY (`id`),
KEY `txn` (`txn`,`line`),
KEY `item` (`item`)
);these tables are both very incomplete — no prices are being tracked here yet, among other things. but this is enough for me to start playing with loading in data and building interfaces to it.
more pieces of the puzzle
back to noodling around with the item table. i think i am going to try and be a bit less deliberative with all of this, since i clearly don’t have a lot of spare time to spend on this and need to build some momentum.
i won’t get into tracking inventory yet, but a basic quality of an item i want to track is a minimum quantity to have on hand. i guess in an ideal system, these minimum quantities would be dynamic and driven by actual sales data, but for now we’ll be hand-tuning this number for items.
an item gets called by its name, so we’ll need a field for that.
so here is our final rough draft of the item table:
CREATE TABLE `item` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`code` varchar(255) NOT NULL,
`name` varchar(255) NOT NULL,
`brand` int(10) unsigned DEFAULT NULL,
`retail_price` decimal(9,2) NOT NULL,
`discount_type` enum('percentage','relative','fixed') DEFAULT NULL,
`discount` decimal(9,2) DEFAULT NULL,
`minimum_quantity` int(10) unsigned NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `code` (`code`)
)and you’ll notice that i snuck in a brand column there, which will be our link over to another table, very basic for now (and maybe for good):
CREATE TABLE `brand` (
`id` int(10) unsigned NOT NULL,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
)we have a nice barcode scanner that we’d like to keep using, so we’ll need to have barcodes we can relate to items. but some items have more than one barcode (common with books that have an ISBN and a UPC), and sometimes things come in packages of one quantity of items that can be decomposed into individual items with different barcodes. so barcodes will live in their own table, and each code will identify an item and a quantity:
CREATE TABLE `barcode` (
`code` varchar(255) NOT NULL,
`item` int(10) unsigned NOT NULL,
`quantity` int(10) unsigned NOT NULL DEFAULT '1',
PRIMARY KEY (`code`),
KEY `item` (`item`)
)we’ll want some more categorization later, but it’s not critical yet. inventory is next, but i am going to have to sleep on it.
no identity crisis
i slipped in a bit to the item table in my nascent point-of-sale system that i introduced last time that i didn’t explain at all. it’s just a little thing, a column called id that is an auto-incrementing integer. we need a way to uniquely identify items, and that’s the fallback method for this broken-down php and mysql coder.*
on the other hand, dealing with ringing up customers and putting together orders from distributors, my experience has been that it is good to have a short-hand identifier for products that is not totally opaque like a bare number. you can see that the developers of php point of sale came to the same conclusion by their inclusion of a item_number field (which is not a number, but we won’t hold that against them). the point-of-sale system we are using currently has a unique identifier for items that they call the code, and the underlying numeric identifiers in the database are never actually exposed in the interface.
the codes we use to identify products are borrowed almost entirely from the way that our primary distributor identifies products. each code has a two letter prefix that identifies the brand of the product, and then the rest of the identifier is structured differently depending on the brand. another of our distributors uses a fairly similar system with the three-letter prefix separated by a dash. depending on the brand and product, this means that looking up similar products can be straightforward if you just remember a part of the code. for example, i have it baked into my brain that all art alternatives studio canvases have a code starting with 'AA55', so doing searches or reports on just those items means i can just type in that prefix instead of having to navigate a more complicated category system. not all of the brands have codes that are structured that conveniently — products from 3M, for example, have a prefix of 'MT' but the rest of the code is based on a portion of the UPC, and a line like all of the command hooks & clips doesn’t sit within the same numeric range so there’s no one prefix that will come up with just those.
another interesting thing to consider is that an identification scheme based on the brand isn’t stable. not too long ago, chartpak acquired the higgins brand from sanford, which meant in the language of the codes that our distributor uses (and we use), the prefix on the higgins items changed from 'SA' to 'CH'. how we track those sort of changes is something we’ll have to consider later, but it does demonstrate that relying on this code as our primary identifier would be unwise.
but i think the real bottom line is that these identifiers are just a unique opaque identifier for the users of the point-of-sale system, so the system doesn’t need to impose any structure on them. in fact, i’m not sure if i can come up with a reason why they shouldn’t be optional, so i’ve left it open to an item not having a code.
so here is the updated table with our newly-minted code field:
CREATE TABLE item (
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
code VARCHAR(255),
retail_price DECIMAL(9,2) NOT NULL,
discount_type ENUM('percentage','relative','fixed'),
discount DECIMAL(9,2),
PRIMARY KEY(id),
UNIQUE (code)
);* so is an auto-incrementing integer really the best primary key to use? it may seem a little more grown-up to use something like a uuid, but while these identifiers may be intended to be hidden, as someone who will almost certainly be looking behind the curtain to run queries against these tables manually, relatively small integers are a whole lot easier to deal with than big hexadecimal ones.
the prices need to be right
i wasn’t entirely truthful when i said i wasn’t sure where to start when writing a point-of-sale system. clearly the place to start is with a model of the data you are going to be handling, and because we are retail store dealing mostly with items out of inventory, describing an item is probably the place to start with that.
php point of sale has a pretty simple item table:
CREATE TABLE `phppos_items` (
`name` varchar(255) NOT NULL,
`category` varchar(255) NOT NULL,
`supplier_id` int(11) DEFAULT NULL,
`item_number` varchar(255) DEFAULT NULL,
`description` varchar(255) NOT NULL,
`cost_price` double(15,2) NOT NULL,
`unit_price` double(15,2) NOT NULL,
`quantity` int(10) NOT NULL DEFAULT '0',
`reorder_level` int(10) NOT NULL DEFAULT '0',
`item_id` int(10) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`item_id`),
UNIQUE KEY `item_number` (`item_number`),
KEY `phppos_items_ibfk_1` (`supplier_id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;it’s not a bad start, but it is very limited. the net cost of an item (cost_price in the table) is not a constant. prices change, different suppliers may charge different prices for the same item, and suppliers often have special deals based on quantity or time. and yes, suppliers with an 's', because we can get many items through more than one supplier.
even just two prices aren’t really enough: most of the items have net prices they are available to us at (depending on supplier and specials), the net price we actually paid for items in inventory, a retail price (also known as msrp), our every-day price (often a fixed percentage discount from msrp), limited-time sale prices, and even discounts based on a quantity of related items being purchased (buy six cans of spray paint, get them all at 25% off instead of 20% off). there’s also the price that someone actually paid for an item when they purchase it, which is usually derived from one of those others but could also be something that we further change or discount for a particular transaction. clearly, two fields in one table doesn’t quite capture this complexity.
if i were to really boil down the pricing in a primary item table, i think the only values that would be necessary are the retail price and our every-day price (expressed as a fixed price, relative price, or discount). even that retail price could arguably draw from the data that our suppliers provide, but we don’t always roll out changes to the suggested retail price at the same time our suppliers may update the pricing, and suppliers may not always agree on what the suggested retail price may be. so here’s my item table so far:
CREATE TABLE item (
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
retail_price DECIMAL(9,2) NOT NULL,
discount_type ENUM('percentage','relative','fixed'),
discount DECIMAL(9,2),
PRIMARY KEY(id)
);obviously i haven’t yet captured all of the complexity that i’ve outlined above, but i’ll get there eventually.
piece of what?
i spend a lot of my day now dealing with a point-of-sale system that bothers me for the same reason that most software bothers me: it is broken and i can’t fix it. in this case, i can’t fix it because it is a closed-source application. one redeeming feature of the software is that it uses postgres as its back-end database, so it is relatively straightforward to get at the raw data and i’m not entirely hobbled by the slow, incomplete interfaces that the software itself offers. (instead i’m just hobbled by its baroque and undocumented schema and an inability to change or add to the data.)
so i have been poking around at the scant open source point-of-sale solutions, and they all generally look terrible, are complicated in directions that i don’t need complication, or are written in stupid languages like java.
php point of sale is way too simplistic, but it has helped me think about how i would (and likely will) build a point-of-sale system. unfortunately, i still haven’t figured out where to start.
so my hope is that if i start writing about it, i will find an entry point and i can eventually start building.