Entries tagged 'open source'
As jacked as it sounds
Dries Buytaert, founder of the Drupal project, wrote a great article on “Solving the Maker-Taker problem,” about how Drupal built a system to recognize the contributions of community members and their sponsors. I am not wild about the “Maker-Taker” terminology because it gives me Election 2012 flashbacks, but I don’t have anything better to propose. (It was this post by Ben Werdmuller that brought the article to my attention.)
By transparently rewarding contributions and fostering collaboration, we can build healthier open source ecosystems. A credit system can help make open source more sustainable and fair, driving growth, competitiveness, and potentially creating thousands of new open source businesses.
It looks like there is a lot to like about the Drupal contribution credit system and their approach to community contribution in general.
This idea of how money and other benefits should flow within the free software (and open source) ecosystem has been on my mind for over 32 years and it is frustrating to me that I still don’t feel like I know how I feel about it.
It has been easy, at times, to feel like I have ended up on the wrong side of the deal. It felt pretty good when I made money (a little) from MySQL’s sale to Sun Microsystems. I also feel pretty dumb when I’m working alongside people on open source projects where they’re getting paid and I’m not, or someone else entirely is landing investments and spinning up large companies based on the work of communities to which I’ve contributed.
But this isn’t just a feeling I have encountered in my open source work, it was also something I felt when we ran our art supply store. It was a frustrating feeling to hustle to cut a good deal for a non-profit organization where you know the staff there is being paid a better salary than you could afford to pay yourself, and more often than not they would just rely on the big online suppliers rather than even bring the business to us, the small local business.
Maybe my feelings are complicated because I never managed to become post-economic. My version of becoming post-economic was supposed to be running an art supply store, and instead it turned me sub-economic.
The rules can matter

I had written a variation of this in a couple of spots now and wanted to put it here, this weird place where I keep writing things:
Organizations with vague rules get captured by people who just fill in the gaps with rules they make up on their own to their own advantage, and then they will continuously find reasons that the “official” rules can’t be fixed because the proposed change is somehow imperfect so they force you to accept the rules they have made up.
The first time I ran into this sort of problem was probably in college being involved in student government, but I haven’t been able to come up with the specifics of what happened that makes me think that it was.
A later instance where I came across it that I remember more vividly was when I was involved with the Downtown Los Angeles Neighborhood Council and how one of the executive board members would squash efforts by citing “standing rules” that nobody could ever substantiate.
More recently, I came across it in looking at discussions of why certain people are or are not allowed to vote on PHP RFCs where the lead developers of one or more popular PHP packages have been shut out because of what I would argue is a misreading of the “Who can vote” section of the Voting Process RFC.
Open source and anxiety triggers
I have been thinking more about bullying in the open source community being a security problem and how part of the process of getting the XZ backdoor into play was playing into the mental health struggles of the original maintainer.
It reminded me of a flawed system that I found having a large impact on my mental health while running our store. Like any diligent small business, we claimed our listings on Yelp and Google and the other major spots where people leave reviews.
I can still feel my stomach dropping when I would get a notification from Yelp that said someone had left a review. Thosee notifications didn’t give the single most critical bit of information: how many stars. Was it going to be a nasty one-star review, or was it someone leaving a wonderful five-star review? No clue! First you have to log in to the Yelp for Business website to see how the rest of your day would feel.
It was the “we need to talk later today” message from your boss that anyone could lob at me at any moment, maybe without even knowing they were doing it.
This was also brought to mind when I read about Daniel Stenberg’s experience with AI-generated security bug reports for curl and besides the aggravation of the reports being nonsense, I could only imagine that adrenaline spike when the report first comes in.
And bringing this back to something I linked to yesterday, where someone from Microsoft reported an issue with ffmpeg as “high priority”. Again, I can imagine one of the maintainers reading this request and feeling that adrenaline spike, that anxiety trigger.
It turns out that it wasn’t even a bug in the project, the reporter just didn’t know the right command line options to use. (I will also point out that they also said they were going to provide updates on whether the free support they received worked, but then they never did.)
Maybe the ffpmeg maintainers and Daniel are good at shrugging this stuff off. I thought I was, but one of the lessons that I learned from running our store is that the effects are cumulative even when individually small, and it is a good idea to figure out how to combat it.
And while there won’t be any simple technical solutions to these human problems in open source, it is very important to make sure whatever tools are being built don’t create these same sorts of anxiety spikes. We need to make sure to build kindness into the tools, whatever they may be.
Maintenance engineer, slightly used
A popular response to the attempted backdooring of the XZ Utils has been people like Tim Bray talking about the maintenance of open source projects and how to pay for them.
When I transitioned from leading the web development team at MySQL to an engineering position in the server team, I spent the first year as a maintenance engineer. I blogged a little about the results of that one year and calculated that I had fixed approximately one reported bug per working day.
But you’ll also notice that I had to heap some praise on Sergei Golubchik who reviewed fixes for even more bugs than I had fixed. (He also was responsible for working on new features. He is extremely talented, and I’m not surprised to see he’s the chief architect at MariaDB.)
That sort of reviewing and pulling in patches is a critical component of maintaining an open source project, and a big problem is that is not all that fun. Writing code? Fun. Fixing bugs? Often fun. Reviewing changes, merging them in, and making releases? A lot less fun. (Building tools to do that? More fun, and can sidetrack people from doing the less-fun part.)
It is also a lot different for projects with a lot of developers, a small crowd of developers, and just a few developers. The process that a patch goes through to make it into the Linux kernel doesn’t necessarily scale down to a project with just a few part-time developers, and vice versa. A long time ago, I made some noise about how MySQL might want to adopt something that looked more like the Linux kernel system of pulling up changes rather than what was the existing system of many developers pushing into the main tree, and nobody seemed very interested.
Anyway, as people think about creating ways of paying people to maintain open source software, I think it is very important to make sure they don’t inadvertently create a system that bullies existing open source project maintainers to make them focus on the less-fun aspects to developing software, because that’s kind of how we got into this latest mess.
You already see that happening with supposed-to-be-helpful supply chain tools demanding that projects jump through hoops to be certified, or packaging tools trying to push their build configuration into projects (with an extra layer of crypto nonsense), or a $3 trillion dollar company demanding a “high priority” bug fix from volunteers.
I am curious to see where these discussions lead, because there is certainly not one easy solution that is going to work everywhere. It will also be interesting to see how quickly they lose steam as we get some distance from the XZ Utils backdoor experience.
(Also, I’m still looking for work, and I’m willing to do the less-fun stuff if the pay is right.)
But I still haven’t found what I’m looking for
I’m still looking for a job.
It is a new month, so I thought it was a good time to raise this flag again, despite it being a bad day to try and be honest and earnest on the internet.
I wish I was the sort of organized that allowed me to run down statistics of how many jobs I have applied to and how many interviews I have gone through other than to say it has been a lot and very few.
Last month I decided to start (re)developing my Python skills because that seems to be much more in demand than the PHP skills I can more obviously lay claim to. I made some contributions to an open source project, ArchiveBox: improving the importing tools, writing tests, and updating it to the latest LTS version of Django from the very old version it was stuck on. I also started putting together a Python library/tool to create a single-file version of an HTML file by pulling in required external resources and in-lining them; my way of learning more about the Python culture and ecosystem.
That and attending SCALE 21x really did help me realize how much I want to be back in the open source development space. I am certainly not dogmatic about it, but I believe to my bones that operating in a community is the best way to develop software.
I think my focus this month has to be on preparing for the “technical interview” exercises that are such a big of the tech hiring process these days, as much as I hate it. I think what makes me a valuable senior engineer is not that I can whip up code on demand for data structures and algorithms, but that I know how to put systems together, have a broader business experience that means I have a deeper of understanding of what matters, and can communicate well. But these tests seem to be an accepted and expected component of the interview process now, so it only makes sense to polish those skills.
(Every day this drags on, I regret my detour into opening a small business more. That debt is going to be a drag on the rest of my life, compounded by the huge weird hole it puts in my résumé.)
Is GitHub becoming SourceForget v2.0?
Back in the day, open source packages used SourceForge for distribution, issue tracking, and other bits of managing the community around projects but it eventually became a wasteland of neglected and abandoned projects and was referred to as SourceForget.
As I have been poking around at adding Markdown parsing and syntax highlighting to my PHP project, I can’t help but feel like GitHub is taking on some of those qualities.
Parsedown is (was?) a popular PHP package for parsing Markdown, but the main branch hasn’t seen any development in at least five years, and the “2.0” branch appears to have stalled out a couple of years ago. Good luck figuring out if any of the 1,100 forks is where active development has moved.
I think it would be good if more community norms and best practices were developed around the idea of the community of a project being able to take over maintenance when the developer steps away. What’s the solution to the thousands of open issues on GitHub that ask if a project is abandoned?
Here is an issue I found on one project where the developer is trying to hand over more access to community members, and I wonder if a guide to taking your project through that transition would have been valuable to move it along.
Another way this comes up that is very relevant is the assertion put forth in “Redis Renamed to Redict” which really asks the question what moral rights the community has to a project.
(SourceForge also came to be loaded down with advertising and I remember it being kind of a miserable website to use, and as GitHub loads up with “AI” features and feels increasingly clunky to use, it’s just another way I wonder if we are seeing history repeat itself.)
Grinding the ArchiveBox
I have been playing around with setting up ArchiveBox so I could use it to archive pages that I bookmark.
I am a long-time, but infrequent, user of Pinboard and have been trying to get in the habit of bookmarking more things. And although my current paid subscription doesn’t run out until 2027, I’m not paying for the archiving feature. So as I thought about how to integrate my bookmarks into this site, I started looking at how I might add that functionality. Pinboard uses wget, which seems simple enough to mimic, and I also found other tools like SingleFile.
That’s when I ran across mention of ArchiveBox and decided that would be a way to have the archiving feature I want and don’t really need/want to expose to the public. So I spun it up on my in-home server, downloaded my bookmarks from Pinboard, and that’s when the coding began.
ArchiveBox was having trouble parsing the RSS feed from Pinboard, and as I started to dig into the code I found that instead of using an actual RSS parser, it was either parsing it using regexes (the generic_rss parser) or an XML parser (the pinboard_rss parser). Both of those seemed insane to me for a Python application to be doing when feedparser has practically been the gold standard of RSS/Atom parsers for 20 years.
After sleeping on it, I decided to roll up my sleeves, bang on some Python code, and produced a pull request that switches to using feedparser. (The big thing I didn’t tackle is adding test cases because I haven’t yet wrapped my head around how to run those for the project when running it within Docker.)
Later, I realized that the RSS feed I was pulling of my bookmarks would be good for pulling on a schedule to keep archiving new bookmarks, but I actually needed to export my full list of bookmarks in JSON format and use that to get everything in the system from the start.
But that importer is broken, too. And again it’s because instead of just using the json parser in the intended way, there was a hack to work around what appears to have been a poor design decision (ArchiveBox would prepend the filename to the file it read the JSON data from when storing it for later reading) that then got another hack piled on top of it when that decision was changed. The generic_json parser used to just always skip the first line of the file, but when that stopped being necessary, that line-skipping wasn’t just removed, it was replaced with some code that suddenly expected the JSON file to look a certain way.
Now I’ve been reading more Python code and writing a little bit, and starting to get more comfortable some of the idioms. I didn’t make a full pull request for it, but my comment on the issue shows a different strategy of trying to parse the file as-is, and if that fails, skip the first line and try it again. That should handle any JSON files with garbage in the first line, such as what ArchiveBox used to store them as. And maybe there is some system out there that exports bookmarks in a format it calls JSON that actually has garbage on the first line. (I hope not.)
So with that workaround applied locally, my Pinboard bookmarks still don’t load because ArchiveBox uses the timestamp of the bookmark as a unique primary key and I have at least a couple of bookmarks that happen to have the same timestamp. I am glad to see that fixing that is project roadmap, but I feel like every time I dig deeper into trying to use ArchiveBox it has me wondering why I didn’t start from scratch and put together what I wanted from more discrete components.
I still like the idea of using ArchiveBox, and it is a good excuse to work on a Python-based project, but sometimes I find myself wondering if I should pay more attention my sense of code smell and just back away slowly.
(My current idea to work around the timestamp collision problem is to add some fake milliseconds to the timestamp as they are all added. That should avoid collisions from a single import. Or I could just edit my Pinboard export and cheat the times to duck the problem.)
what is fair?
Linux has been written entirely by volunteers who have been working on their own time, and I don't think that should change. I also don't think it's fair that someone take what has been written for free by people and try and sell it to turn a buck (i.e. make a living doing so). How fair is that to those of us who contribute our time freely?
i am not sure when it shifted, if it was gradual or sudden, but i do not agree with what i wrote back then (1992!) about the fairness of someone building a business on what someone else has given freely. that has always been a central tension in what became known as the open source community, and you even see it coming up in current discussions about the training data used by generative “AI” systems.
(also, another quote: “I cannot see Linux being a full-time thing for anyone at this point, really.” oops!)
cranking along
a few weeks ago, i got it in my head that the ideal time to switch to using scat, the web-based point-of-sale system that i have allegedly been working on for almost 18 months, would be after the new year. this is despite the fact that it was barely even a rough prototype of some ideas. but i’ve been cranking along on it over the last couple of weeks, and it looks like i might just have something that we can use by my arbitrary deadline.
it’s still just barely a rough prototype of ideas, but i there should be enough there on the surface for us to be able to use it, and needing to fill in the gaps because we are actually using it will probably provide plenty of motivation to make it better.
even in the very rough state it is in, it should alleviate some of the pains of our current system. and save us the $30/month we were paying for not-very-helpful support and slow-to-arrive upgrades (trading that for my time to support the new system, of course).
banker’s round for mysql
for some reason, nobody has ever exposed the different rounding methods via mysql’s built-in ROUND() function, so if you want something different, you need to add it via a stored function. the function below is based on the T-SQL version here.
CREATE FUNCTION ROUND_TO_EVEN(val DECIMAL(32,16), places INT)
RETURNS DECIMAL(32,16)
BEGIN
RETURN IF(ABS(val - TRUNCATE(val, places)) * POWER(10, places + 1) = 5
AND NOT CONVERT(TRUNCATE(ABS(val) * POWER(10, places), 0),
UNSIGNED) % 2 = 1,
TRUNCATE(val, places), ROUND(val, places));
END;
use at your own risk. there may be edge conditions where this fails. but this matches up with the python and postgres based system i was crunching data from, except in cases where that system gets it wrong for some reason.
one thing you might notice is that it does not use any string-handling functions like the other “correct” solution floating around out there.
building an order
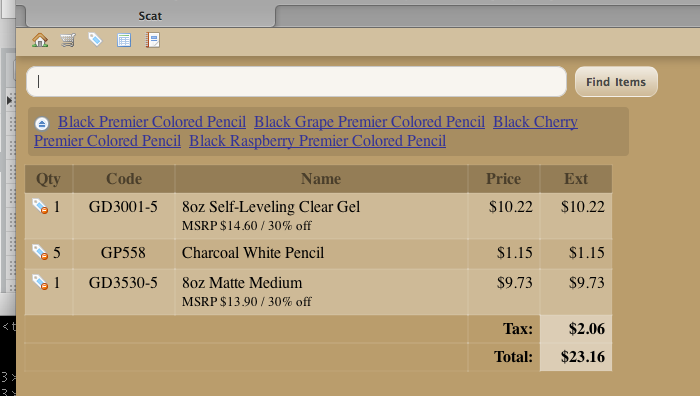
it feels like i’ve been thinking about this point-of-sale thing long enough that when i find time to sit down and write some code, the pieces actually fall together pretty quickly. today i was able to rough together an order-building interface with a few bells and whistles (literally: it has audible cues).
still a long way to go, but this should be a useful little toy to let us take advantage of a spare computer and barcode scanner to more easily price items from incoming shipments and get them out on the shelves.
one of the things that this screenshot shows is what happens when a scan or search matches multiple different items — it adds a (crudely presented) list of the possible matches, and clicking on any one of them adds that item to the order.
three kinds of people
progress on scat continues to be slow, because i have not found a lot of time to work on it. but every week i have to deal with processing our weekly in-take of products with our current point-of-sale system, i kick myself a little more and get motivated to spend a little more time on it.
the big addition today was a table for people, which is pretty straightforward. our current system divides people up into three types (and stores them in the same table as products, thanks to a normalization scheme i have not carried over into scat), and currently i don’t make any such distinction because sometimes customers can become employees and vendors can be customers and we have few enough of all three that keeping them distinct doesn’t seem worth the extra complexity.
scattered progress
scat is the name of the web-based point-of-sale system that i’ve been working on. you might have guessed this if you had been paying attention to the tags on my earlier posts. you can also find the source code for scat on github. there is not much to see, as i am still tinkering and throwing code together to test ideas out.
the progress so far is that i can load all of the item data over from our checkout data, and search those items. one of the most painful things for us right now is receiving orders, so i have cobbled together the start of that functionality to use. we will be able to receive the order using this as we unpack the order, and then go back to checkout and receive the order there all at once through its stock room interface.
(the reason that receiving orders through checkout is so painful for us is that using the stock room interface cripples the performance of checkout. and since we are just using checkout on a single computer, it makes it hard to receive orders while we also want to serve customers.)
this is starting to get fun.
stuff in, stuff out
i know that i said that inventory is next, but i’m not sure that it really is, or at least not in terms of thinking of having an inventory that we add items into and out of. maybe what we really have is a collection of transactions that in their aggregate can be used to describe the inventory.
as i see it, there are three types of transactions:
- vendor transactions: we put together a purchase order, we receive items (which may be more or less than what is on the purchase order and may not happen all at once), and we return items.
- customer transactions: customers order items, we “deliver” items, and customers return items.
- internal transactions: items are damaged, defective or stolen, and we take items for our own use.
so we’ll need a basic table for tracking these transactions (which i will abbreviate to txn because i am lazy):
CREATE TABLE `txn` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`number` int(10) unsigned NOT NULL,
`created` datetime NOT NULL,
`type` enum('internal','vendor','customer') NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `type` (`type`,`number`)
)i am not thrilled with the number field, but we need some sort of user-visible number for printing on invoices, receipts, etc. consider this a placeholder for a better idea.
and for each transaction, we will have lines of items involved:
CREATE TABLE `txn_line` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`txn` int(10) unsigned NOT NULL,
`line` int(10) unsigned NOT NULL,
`item` int(10) unsigned DEFAULT NULL,
`ordered` int(10) unsigned NOT NULL,
`allocated` int(10) unsigned NOT NULL,
PRIMARY KEY (`id`),
KEY `txn` (`txn`,`line`),
KEY `item` (`item`)
);these tables are both very incomplete — no prices are being tracked here yet, among other things. but this is enough for me to start playing with loading in data and building interfaces to it.
more pieces of the puzzle
back to noodling around with the item table. i think i am going to try and be a bit less deliberative with all of this, since i clearly don’t have a lot of spare time to spend on this and need to build some momentum.
i won’t get into tracking inventory yet, but a basic quality of an item i want to track is a minimum quantity to have on hand. i guess in an ideal system, these minimum quantities would be dynamic and driven by actual sales data, but for now we’ll be hand-tuning this number for items.
an item gets called by its name, so we’ll need a field for that.
so here is our final rough draft of the item table:
CREATE TABLE `item` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`code` varchar(255) NOT NULL,
`name` varchar(255) NOT NULL,
`brand` int(10) unsigned DEFAULT NULL,
`retail_price` decimal(9,2) NOT NULL,
`discount_type` enum('percentage','relative','fixed') DEFAULT NULL,
`discount` decimal(9,2) DEFAULT NULL,
`minimum_quantity` int(10) unsigned NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `code` (`code`)
)and you’ll notice that i snuck in a brand column there, which will be our link over to another table, very basic for now (and maybe for good):
CREATE TABLE `brand` (
`id` int(10) unsigned NOT NULL,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
)we have a nice barcode scanner that we’d like to keep using, so we’ll need to have barcodes we can relate to items. but some items have more than one barcode (common with books that have an ISBN and a UPC), and sometimes things come in packages of one quantity of items that can be decomposed into individual items with different barcodes. so barcodes will live in their own table, and each code will identify an item and a quantity:
CREATE TABLE `barcode` (
`code` varchar(255) NOT NULL,
`item` int(10) unsigned NOT NULL,
`quantity` int(10) unsigned NOT NULL DEFAULT '1',
PRIMARY KEY (`code`),
KEY `item` (`item`)
)we’ll want some more categorization later, but it’s not critical yet. inventory is next, but i am going to have to sleep on it.
no identity crisis
i slipped in a bit to the item table in my nascent point-of-sale system that i introduced last time that i didn’t explain at all. it’s just a little thing, a column called id that is an auto-incrementing integer. we need a way to uniquely identify items, and that’s the fallback method for this broken-down php and mysql coder.*
on the other hand, dealing with ringing up customers and putting together orders from distributors, my experience has been that it is good to have a short-hand identifier for products that is not totally opaque like a bare number. you can see that the developers of php point of sale came to the same conclusion by their inclusion of a item_number field (which is not a number, but we won’t hold that against them). the point-of-sale system we are using currently has a unique identifier for items that they call the code, and the underlying numeric identifiers in the database are never actually exposed in the interface.
the codes we use to identify products are borrowed almost entirely from the way that our primary distributor identifies products. each code has a two letter prefix that identifies the brand of the product, and then the rest of the identifier is structured differently depending on the brand. another of our distributors uses a fairly similar system with the three-letter prefix separated by a dash. depending on the brand and product, this means that looking up similar products can be straightforward if you just remember a part of the code. for example, i have it baked into my brain that all art alternatives studio canvases have a code starting with 'AA55', so doing searches or reports on just those items means i can just type in that prefix instead of having to navigate a more complicated category system. not all of the brands have codes that are structured that conveniently — products from 3M, for example, have a prefix of 'MT' but the rest of the code is based on a portion of the UPC, and a line like all of the command hooks & clips doesn’t sit within the same numeric range so there’s no one prefix that will come up with just those.
another interesting thing to consider is that an identification scheme based on the brand isn’t stable. not too long ago, chartpak acquired the higgins brand from sanford, which meant in the language of the codes that our distributor uses (and we use), the prefix on the higgins items changed from 'SA' to 'CH'. how we track those sort of changes is something we’ll have to consider later, but it does demonstrate that relying on this code as our primary identifier would be unwise.
but i think the real bottom line is that these identifiers are just a unique opaque identifier for the users of the point-of-sale system, so the system doesn’t need to impose any structure on them. in fact, i’m not sure if i can come up with a reason why they shouldn’t be optional, so i’ve left it open to an item not having a code.
so here is the updated table with our newly-minted code field:
CREATE TABLE item (
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
code VARCHAR(255),
retail_price DECIMAL(9,2) NOT NULL,
discount_type ENUM('percentage','relative','fixed'),
discount DECIMAL(9,2),
PRIMARY KEY(id),
UNIQUE (code)
);* so is an auto-incrementing integer really the best primary key to use? it may seem a little more grown-up to use something like a uuid, but while these identifiers may be intended to be hidden, as someone who will almost certainly be looking behind the curtain to run queries against these tables manually, relatively small integers are a whole lot easier to deal with than big hexadecimal ones.
the prices need to be right
i wasn’t entirely truthful when i said i wasn’t sure where to start when writing a point-of-sale system. clearly the place to start is with a model of the data you are going to be handling, and because we are retail store dealing mostly with items out of inventory, describing an item is probably the place to start with that.
php point of sale has a pretty simple item table:
CREATE TABLE `phppos_items` (
`name` varchar(255) NOT NULL,
`category` varchar(255) NOT NULL,
`supplier_id` int(11) DEFAULT NULL,
`item_number` varchar(255) DEFAULT NULL,
`description` varchar(255) NOT NULL,
`cost_price` double(15,2) NOT NULL,
`unit_price` double(15,2) NOT NULL,
`quantity` int(10) NOT NULL DEFAULT '0',
`reorder_level` int(10) NOT NULL DEFAULT '0',
`item_id` int(10) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`item_id`),
UNIQUE KEY `item_number` (`item_number`),
KEY `phppos_items_ibfk_1` (`supplier_id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;it’s not a bad start, but it is very limited. the net cost of an item (cost_price in the table) is not a constant. prices change, different suppliers may charge different prices for the same item, and suppliers often have special deals based on quantity or time. and yes, suppliers with an 's', because we can get many items through more than one supplier.
even just two prices aren’t really enough: most of the items have net prices they are available to us at (depending on supplier and specials), the net price we actually paid for items in inventory, a retail price (also known as msrp), our every-day price (often a fixed percentage discount from msrp), limited-time sale prices, and even discounts based on a quantity of related items being purchased (buy six cans of spray paint, get them all at 25% off instead of 20% off). there’s also the price that someone actually paid for an item when they purchase it, which is usually derived from one of those others but could also be something that we further change or discount for a particular transaction. clearly, two fields in one table doesn’t quite capture this complexity.
if i were to really boil down the pricing in a primary item table, i think the only values that would be necessary are the retail price and our every-day price (expressed as a fixed price, relative price, or discount). even that retail price could arguably draw from the data that our suppliers provide, but we don’t always roll out changes to the suggested retail price at the same time our suppliers may update the pricing, and suppliers may not always agree on what the suggested retail price may be. so here’s my item table so far:
CREATE TABLE item (
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
retail_price DECIMAL(9,2) NOT NULL,
discount_type ENUM('percentage','relative','fixed'),
discount DECIMAL(9,2),
PRIMARY KEY(id)
);obviously i haven’t yet captured all of the complexity that i’ve outlined above, but i’ll get there eventually.
piece of what?
i spend a lot of my day now dealing with a point-of-sale system that bothers me for the same reason that most software bothers me: it is broken and i can’t fix it. in this case, i can’t fix it because it is a closed-source application. one redeeming feature of the software is that it uses postgres as its back-end database, so it is relatively straightforward to get at the raw data and i’m not entirely hobbled by the slow, incomplete interfaces that the software itself offers. (instead i’m just hobbled by its baroque and undocumented schema and an inability to change or add to the data.)
so i have been poking around at the scant open source point-of-sale solutions, and they all generally look terrible, are complicated in directions that i don’t need complication, or are written in stupid languages like java.
php point of sale is way too simplistic, but it has helped me think about how i would (and likely will) build a point-of-sale system. unfortunately, i still haven’t figured out where to start.
so my hope is that if i start writing about it, i will find an entry point and i can eventually start building.
what is 10% of php worth?
i am listed as one of the ten members of the php group. most of the php source code says it is copyright “the php group” (except for the zend engine stuff). the much-debated contributor license agreement for PDO2 involves the php group.
could i assign whatever rights (and responsibilities) my membership in the php group represents to someone else? how much should i try to get for it? i mean, if mysql was worth $1 billion....
i am still disappointed that a way of evolving the membership of the php group was never established.
being known for being you
mike kruckenberg shared his observations from watching mysql source code commits, and jay pipes commented about this commit from antony curtis which had him excited. now that’s how open source is supposed to work, at least in part.
i replied to a later version of that commit to our internal developer list (and antony), pointing out that with just a little effort the comment would be more useful to people outside of the development team. “plugin server variables” doesn’t really do it justice, and “WL 2936” is useful to people who can access our internal task tracking tool, but does no good to people like mike.
the other reason it is good to engage the community like this is because it is very healthy for your own future. being able to point to the work i had done on open source and the networking that came from that have both been key factors in getting jobs for me. i’m sure it will be useful next time i am looking, too.
producing open source software by karl fogel (hardcopy) looks to be a very good book about the human side of producing open-source software.
blogging.la follows up on the old proposal for the city of los angeles to adopt open source and apply the money saved to hiring more police officers, and finds that the proposal appears to have gone off the rails. i wish i could say i was surprised.
but something that comes out in the report filed about current open source usage by the city is there are several departments using mysql, including the city ethics commission, and several others that think they could use it. cool.
democratizing development
democratizing innovation by eric von hippel is a fairly dry, academic business book, which made it tougher than i had expected to get through. there are some interesting observations and insights in the book, but they are perhaps too few and far between. you can read the book online.
over on planet mysql, the related topic of distributed version control has gotten some attention, with some shout-outs to free tools for doing distributed development. (i’ll add one for mercurial.)
ian bicking tries to argue in favor of centralized scm systems, but i think he’s neglecting the cost imposed on the center of the project by such centralized systems that the distributed systems do a really good job of distributing — you can impose something even better than his proposed “we don’t accept patches, we only accept pointers to branches in our repository” — “we don’t accept patches, we only pull changes from publically-available repositories.”
i can’t imagine the security nightmare of providing global check-in access to everyone, and the complexity of tools that would be required to manage the layers of dead-end branches.
left hand, meet the right hand
james gosling, who inflicted java on the world, had some interesting things to say about open-source companies:
Open source vendors also came under fire, with Gosling sideswiping MySQL, JBoss, and Red Hat: “They say that they are running their businesses based on services.
“These businesses are more hype than reality. If they don’t have a [longer term] economic model…they are going to have a really hard time.”
apparently he didn’t get the memo.
but i guess if anyone would be an expert on companies that lack financial viability, it would be an executive at sun.
i also love the other juxtaposition in the article: mysql isn’t open source because “no one is allowed to do check-ins,” but java is open-source, because the source has always been available.
city of angels to adopt open source?
a few los angeles city councilmembers have introduced a measure to have the city study using open-source software, and putting the possible money saved towards hiring new police officers. it sounds like a great plan, and i hope to get around to writing my city councilmember soon to encourage her to support the motion.
speaking of my city councilmember, i have gotten four calls from her campaign in the last few days. one of them was actually from the councilmember herself (before this open-source motion came up) due to some sort of mix-up by her campaign staff that led her to believe i had some issue i wanted to discuss. as i was sucking on the world of warcrack pipe at the time, i was in no mood to talk to her. then today was call number four, and i pointed out to the caller that if they called me again, i would almost certainly not vote for her in the upcoming primary. (the only other call i’ve gotten is from the bernard parks mayoral campaign.)